深度学习之目标检测SSD
What is SSD?
关于目标检测算法,当下已经有很多优秀的开源算法,其中算法主要分为两类:one-stage 和 two-stage。本次介绍的SSD算法就是one-stage算法的一种。主要的工作流程就是在利用主流的特征提取网络提取特征后,根据特征维度在图片上的不同位置进行密集采样,每个采样点都包含不同尺度和长宽比的先验框,然后对不同的先验框中的物体种类进行预测和相对于预测框位置进行回归,速度较快。
但是针对密集采样,由于采样点较多,且可能多数点都不存在目标,所以容易导致正负样本不平衡,从而使得训练难度上升。
主干网络结构简介
针对SSD算法,其中主要利用的是VGG16作为主干特征提取网络,并且将VGG16中的FC6和FC7两层转换为卷积层,去掉所有的丢弃层和FC8层,并增加Conv8和Conv9。由于之前文章中已经介绍过VGG16,所以此处不再重复介绍。
本文此次以SSD300为例,介绍SSD算法,网络结构如下: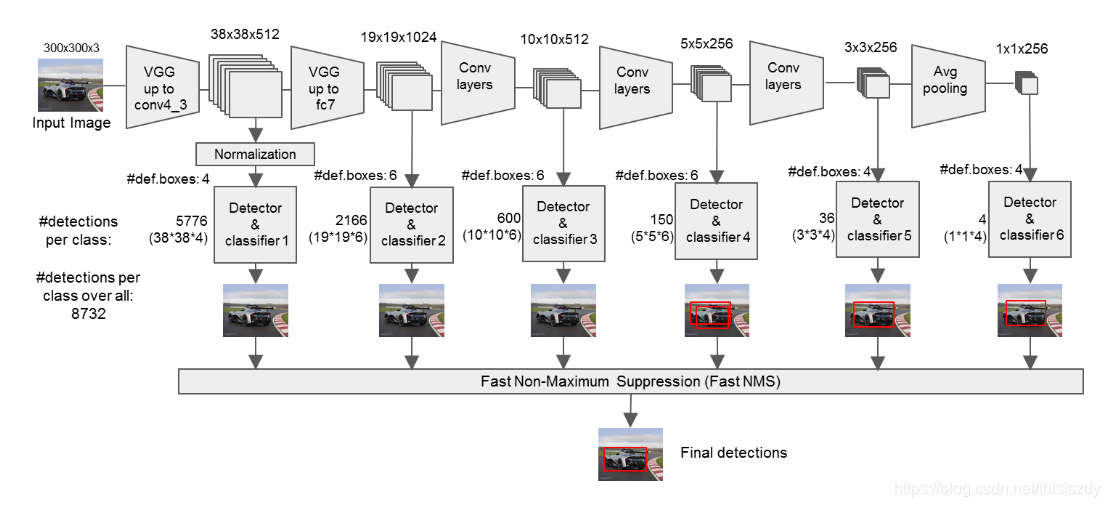
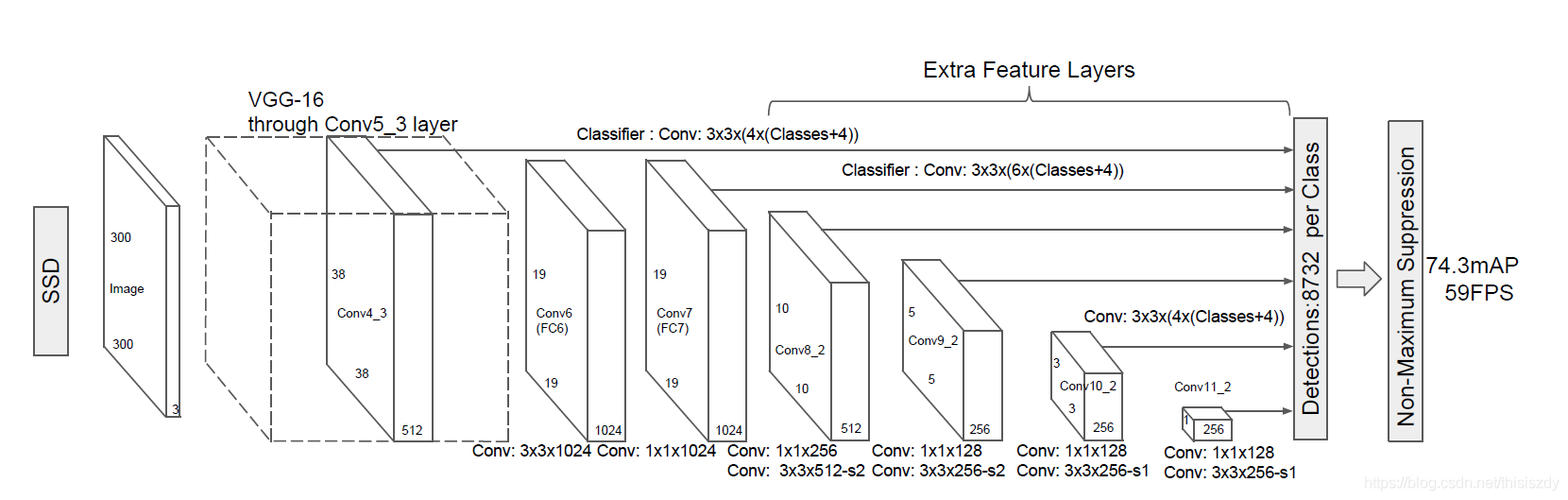
网络处理流程:
- 输入图片首先resize到300x300大小的图片
- 2次(3,3)卷积,1次(2,2)池化
- 2次(3,3)卷积,1次(2,2)池化
- 3次(3,3)卷积,1次(2,2)池化
- 3次(3,3)卷积,1次(2,2)池化
- 3次(3,3)卷积,1次(2,2)池化
- 1次(3,3)卷积,1次(1,1)卷积
- 1次(1,1)卷积,1次(3,3)卷积,步长2
- 1次(1,1)卷积,1次(3,3)卷积,步长2
- 1次(1,1)卷积,1次(3,3)卷积,padding = vaild
- 1次(1,1)卷积,1次(3,3)卷积,padding = vaild
代码如下:
def VGG16(input_tensor):
net = {}
# Block 1
net['input'] = input_tensor
# 300,300,3 -> 150,150,64
net['conv1_1'] = Conv2D(64, kernel_size=(3,3), activation='relu', padding='same', name='conv1_1')(net['input'])
net['conv1_2'] = Conv2D(64, kernel_size=(3,3), activation='relu', padding='same', name='conv1_2')(net['conv1_1'])
net['pool1'] = MaxPooling2D((2, 2), strides=(2, 2), padding='same', name='pool1')(net['conv1_2'])
# Block 2
# 150,150,64 -> 75,75,128
net['conv2_1'] = Conv2D(128, kernel_size=(3,3), activation='relu', padding='same', name='conv2_1')(net['pool1'])
net['conv2_2'] = Conv2D(128, kernel_size=(3,3), activation='relu', padding='same', name='conv2_2')(net['conv2_1'])
net['pool2'] = MaxPooling2D((2, 2), strides=(2, 2), padding='same', name='pool2')(net['conv2_2'])
# Block 3
# 75,75,128 -> 38,38,256
net['conv3_1'] = Conv2D(256, kernel_size=(3,3), activation='relu', padding='same', name='conv3_1')(net['pool2'])
net['conv3_2'] = Conv2D(256, kernel_size=(3,3), activation='relu', padding='same', name='conv3_2')(net['conv3_1'])
net['conv3_3'] = Conv2D(256, kernel_size=(3,3), activation='relu', padding='same', name='conv3_3')(net['conv3_2'])
net['pool3'] = MaxPooling2D((2, 2), strides=(2, 2), padding='same', name='pool3')(net['conv3_3'])
# Block 4
# 38,38,256 -> 19,19,512
net['conv4_1'] = Conv2D(512, kernel_size=(3,3), activation='relu', padding='same', name='conv4_1')(net['pool3'])
net['conv4_2'] = Conv2D(512, kernel_size=(3,3), activation='relu', padding='same', name='conv4_2')(net['conv4_1'])
net['conv4_3'] = Conv2D(512, kernel_size=(3,3), activation='relu', padding='same', name='conv4_3')(net['conv4_2'])
net['pool4'] = MaxPooling2D((2, 2), strides=(2, 2), padding='same', name='pool4')(net['conv4_3'])
# Block 5
# 19,19,512 -> 19,19,512
net['conv5_1'] = Conv2D(512, kernel_size=(3,3), activation='relu', padding='same', name='conv5_1')(net['pool4'])
net['conv5_2'] = Conv2D(512, kernel_size=(3,3), activation='relu', padding='same', name='conv5_2')(net['conv5_1'])
net['conv5_3'] = Conv2D(512, kernel_size=(3,3), activation='relu', padding='same', name='conv5_3')(net['conv5_2'])
net['pool5'] = MaxPooling2D((3, 3), strides=(1, 1), padding='same', name='pool5')(net['conv5_3'])
# FC6
# 19,19,512 -> 19,19,1024
net['fc6'] = Conv2D(1024, kernel_size=(3,3), dilation_rate=(6, 6), activation='relu', padding='same', name='fc6')(net['pool5'])
# x = Dropout(0.5, name='drop6')(x)
# FC7
# 19,19,1024 -> 19,19,1024
net['fc7'] = Conv2D(1024, kernel_size=(1,1), activation='relu', padding='same', name='fc7')(net['fc6'])
# x = Dropout(0.5, name='drop7')(x)
# Block 6
# 19,19,512 -> 10,10,512
net['conv6_1'] = Conv2D(256, kernel_size=(1,1), activation='relu', padding='same', name='conv6_1')(net['fc7'])
net['conv6_2'] = ZeroPadding2D(padding=((1, 1), (1, 1)), name='conv6_padding')(net['conv6_1'])
net['conv6_2'] = Conv2D(512, kernel_size=(3,3), strides=(2, 2), activation='relu', name='conv6_2')(net['conv6_2'])
# Block 7
# 10,10,512 -> 5,5,256
net['conv7_1'] = Conv2D(128, kernel_size=(1,1), activation='relu', padding='same', name='conv7_1')(net['conv6_2'])
net['conv7_2'] = ZeroPadding2D(padding=((1, 1), (1, 1)), name='conv7_padding')(net['conv7_1'])
net['conv7_2'] = Conv2D(256, kernel_size=(3,3), strides=(2, 2), activation='relu', padding='valid', name='conv7_2')(net['conv7_2'])
# Block 8
# 5,5,256 -> 3,3,256
net['conv8_1'] = Conv2D(128, kernel_size=(1,1), activation='relu', padding='same', name='conv8_1')(net['conv7_2'])
net['conv8_2'] = Conv2D(256, kernel_size=(3,3), strides=(1, 1), activation='relu', padding='valid', name='conv8_2')(net['conv8_1'])
# Block 9
# 3,3,256 -> 1,1,256
net['conv9_1'] = Conv2D(128, kernel_size=(1,1), activation='relu', padding='same', name='conv9_1')(net['conv8_2'])
net['conv9_2'] = Conv2D(256, kernel_size=(3,3), strides=(1, 1), activation='relu', padding='valid', name='conv9_2')(net['conv9_1'])
return net
构建预测值
SSD网络的最后预测值主要包含三个部分:
net{‘mbox_loc’}:先验框的预期位置——包含目标的先验框相对于其匹配的真实框的中心xy位移和长宽缩放比
net{‘mbox_conf’}:先验框中的目标类别——one-hot编码后softmax进行分类
net{‘mbox_priorbox’}:先验框的原始位置以及variances(用于预测框解码或编码)——这部分不进行训练,只作为预测结果的辅助使用
其中按照SSD300的输入大小,先验框的数量为8732个。
代码如下:def SSD300(input_shape, num_classes=21): # 300,300,3 input_tensor = Input(shape=input_shape) img_size = (input_shape[1], input_shape[0]) # SSD结构,net字典 net = VGG16(input_tensor) #-----------------------将提取到的主干特征进行处理---------------------------# # 对conv4_3进行处理 38,38,512 net['conv4_3_norm'] = Normalize(20, name='conv4_3_norm')(net['conv4_3']) num_priors = 4 # 预测框的处理 # num_priors表示每个网格点先验框的数量,4是x,y,h,w的调整 net['conv4_3_norm_mbox_loc'] = Conv2D(num_priors * 4, kernel_size=(3,3), padding='same', name='conv4_3_norm_mbox_loc')(net['conv4_3_norm']) net['conv4_3_norm_mbox_loc_flat'] = Flatten(name='conv4_3_norm_mbox_loc_flat')(net['conv4_3_norm_mbox_loc']) # num_priors表示每个网格点先验框的数量,num_classes是所分的类 net['conv4_3_norm_mbox_conf'] = Conv2D(num_priors * num_classes, kernel_size=(3,3), padding='same',name='conv4_3_norm_mbox_conf')(net['conv4_3_norm']) net['conv4_3_norm_mbox_conf_flat'] = Flatten(name='conv4_3_norm_mbox_conf_flat')(net['conv4_3_norm_mbox_conf']) priorbox = PriorBox(img_size, 30.0,max_size = 60.0, aspect_ratios=[2], variances=[0.1, 0.1, 0.2, 0.2], name='conv4_3_norm_mbox_priorbox') net['conv4_3_norm_mbox_priorbox'] = priorbox(net['conv4_3_norm']) # 对fc7层进行处理 num_priors = 6 # 预测框的处理 # num_priors表示每个网格点先验框的数量,4是x,y,h,w的调整 net['fc7_mbox_loc'] = Conv2D(num_priors * 4, kernel_size=(3,3),padding='same',name='fc7_mbox_loc')(net['fc7']) net['fc7_mbox_loc_flat'] = Flatten(name='fc7_mbox_loc_flat')(net['fc7_mbox_loc']) # num_priors表示每个网格点先验框的数量,num_classes是所分的类 net['fc7_mbox_conf'] = Conv2D(num_priors * num_classes, kernel_size=(3,3),padding='same',name='fc7_mbox_conf')(net['fc7']) net['fc7_mbox_conf_flat'] = Flatten(name='fc7_mbox_conf_flat')(net['fc7_mbox_conf']) priorbox = PriorBox(img_size, 60.0, max_size=111.0, aspect_ratios=[2, 3], variances=[0.1, 0.1, 0.2, 0.2], name='fc7_mbox_priorbox') net['fc7_mbox_priorbox'] = priorbox(net['fc7']) # 对conv6_2进行处理 num_priors = 6 # 预测框的处理 # num_priors表示每个网格点先验框的数量,4是x,y,h,w的调整 x = Conv2D(num_priors * 4, kernel_size=(3,3), padding='same',name='conv6_2_mbox_loc')(net['conv6_2']) net['conv6_2_mbox_loc'] = x net['conv6_2_mbox_loc_flat'] = Flatten(name='conv6_2_mbox_loc_flat')(net['conv6_2_mbox_loc']) # num_priors表示每个网格点先验框的数量,num_classes是所分的类 x = Conv2D(num_priors * num_classes, kernel_size=(3,3), padding='same',name='conv6_2_mbox_conf')(net['conv6_2']) net['conv6_2_mbox_conf'] = x net['conv6_2_mbox_conf_flat'] = Flatten(name='conv6_2_mbox_conf_flat')(net['conv6_2_mbox_conf']) priorbox = PriorBox(img_size, 111.0, max_size=162.0, aspect_ratios=[2, 3], variances=[0.1, 0.1, 0.2, 0.2], name='conv6_2_mbox_priorbox') net['conv6_2_mbox_priorbox'] = priorbox(net['conv6_2']) # 对conv7_2进行处理 num_priors = 6 # 预测框的处理 # num_priors表示每个网格点先验框的数量,4是x,y,h,w的调整 x = Conv2D(num_priors * 4, kernel_size=(3,3), padding='same',name='conv7_2_mbox_loc')(net['conv7_2']) net['conv7_2_mbox_loc'] = x net['conv7_2_mbox_loc_flat'] = Flatten(name='conv7_2_mbox_loc_flat')(net['conv7_2_mbox_loc']) # num_priors表示每个网格点先验框的数量,num_classes是所分的类 x = Conv2D(num_priors * num_classes, kernel_size=(3,3), padding='same',name='conv7_2_mbox_conf')(net['conv7_2']) net['conv7_2_mbox_conf'] = x net['conv7_2_mbox_conf_flat'] = Flatten(name='conv7_2_mbox_conf_flat')(net['conv7_2_mbox_conf']) priorbox = PriorBox(img_size, 162.0, max_size=213.0, aspect_ratios=[2, 3], variances=[0.1, 0.1, 0.2, 0.2], name='conv7_2_mbox_priorbox') net['conv7_2_mbox_priorbox'] = priorbox(net['conv7_2']) # 对conv8_2进行处理 num_priors = 4 # 预测框的处理 # num_priors表示每个网格点先验框的数量,4是x,y,h,w的调整 x = Conv2D(num_priors * 4, kernel_size=(3,3), padding='same',name='conv8_2_mbox_loc')(net['conv8_2']) net['conv8_2_mbox_loc'] = x net['conv8_2_mbox_loc_flat'] = Flatten(name='conv8_2_mbox_loc_flat')(net['conv8_2_mbox_loc']) # num_priors表示每个网格点先验框的数量,num_classes是所分的类 x = Conv2D(num_priors * num_classes, kernel_size=(3,3), padding='same',name='conv8_2_mbox_conf')(net['conv8_2']) net['conv8_2_mbox_conf'] = x net['conv8_2_mbox_conf_flat'] = Flatten(name='conv8_2_mbox_conf_flat')(net['conv8_2_mbox_conf']) priorbox = PriorBox(img_size, 213.0, max_size=264.0, aspect_ratios=[2], variances=[0.1, 0.1, 0.2, 0.2], name='conv8_2_mbox_priorbox') net['conv8_2_mbox_priorbox'] = priorbox(net['conv8_2']) # 对conv9_2进行处理 num_priors = 4 # 预测框的处理 # num_priors表示每个网格点先验框的数量,4是x,y,h,w的调整 x = Conv2D(num_priors * 4, kernel_size=(3,3), padding='same',name='conv9_2_mbox_loc')(net['conv9_2']) net['conv9_2_mbox_loc'] = x net['conv9_2_mbox_loc_flat'] = Flatten(name='conv9_2_mbox_loc_flat')(net['conv9_2_mbox_loc']) # num_priors表示每个网格点先验框的数量,num_classes是所分的类 x = Conv2D(num_priors * num_classes, kernel_size=(3,3), padding='same',name='conv9_2_mbox_conf')(net['conv9_2']) net['conv9_2_mbox_conf'] = x net['conv9_2_mbox_conf_flat'] = Flatten(name='conv9_2_mbox_conf_flat')(net['conv9_2_mbox_conf']) priorbox = PriorBox(img_size, 264.0, max_size=315.0, aspect_ratios=[2], variances=[0.1, 0.1, 0.2, 0.2], name='conv9_2_mbox_priorbox') net['conv9_2_mbox_priorbox'] = priorbox(net['conv9_2']) # 将所有结果进行堆叠 net['mbox_loc'] = concatenate([net['conv4_3_norm_mbox_loc_flat'], net['fc7_mbox_loc_flat'], net['conv6_2_mbox_loc_flat'], net['conv7_2_mbox_loc_flat'], net['conv8_2_mbox_loc_flat'], net['conv9_2_mbox_loc_flat']], axis=1, name='mbox_loc') net['mbox_conf'] = concatenate([net['conv4_3_norm_mbox_conf_flat'], net['fc7_mbox_conf_flat'], net['conv6_2_mbox_conf_flat'], net['conv7_2_mbox_conf_flat'], net['conv8_2_mbox_conf_flat'], net['conv9_2_mbox_conf_flat']], axis=1, name='mbox_conf') # 先验框的位置和辅助变量 net['mbox_priorbox'] = concatenate([net['conv4_3_norm_mbox_priorbox'], net['fc7_mbox_priorbox'], net['conv6_2_mbox_priorbox'], net['conv7_2_mbox_priorbox'], net['conv8_2_mbox_priorbox'], net['conv9_2_mbox_priorbox']], axis=1, name='mbox_priorbox') if hasattr(net['mbox_loc'], '_keras_shape'): num_boxes = net['mbox_loc']._keras_shape[-1] // 4 elif hasattr(net['mbox_loc'], 'int_shape'): num_boxes = K.int_shape(net['mbox_loc'])[-1] // 4 # 预期位置 net['mbox_loc'] = Reshape((num_boxes, 4),name='mbox_loc_final')(net['mbox_loc']) # 分类结果 net['mbox_conf'] = Reshape((num_boxes, num_classes),name='mbox_conf_logits')(net['mbox_conf']) net['mbox_conf'] = Activation('softmax',name='mbox_conf_final')(net['mbox_conf']) net['predictions'] = concatenate([net['mbox_loc'], net['mbox_conf'], net['mbox_priorbox']], axis=2, name='predictions') print(net['predictions']) model = Model(net['input'], net['predictions']) return model
先验框编码与解码
针对先验框的编码过程,即计算net{‘mbox_loc’}——先验框的预期位置。
- 找到与真实框重合度高于某个阈值(如0.5)的所有先验框
- 根据先验框匹配的真实框进行编码得到预期位置
- 然后根据one-hot编码,将目标类别进行编码
- 最后的先验框原始位置和variances值不需要进行提取,只添加一个是否包含物体的判断值即可,用于loss计算
def encode_box(self, box, return_iou=True):
iou = self.iou(box)
encoded_box = np.zeros((self.num_priors, 4 + return_iou))
# 找到每一个真实框,重合程度较高的先验框
assign_mask = iou > self.overlap_threshold
if not assign_mask.any():
assign_mask[iou.argmax()] = True
if return_iou:
encoded_box[:, -1][assign_mask] = iou[assign_mask]
# 找到对应的先验框
assigned_priors = self.priors[assign_mask]
# 逆向编码,将真实框转化为ssd预测结果的格式
# 先计算真实框的中心与长宽
box_center = 0.5 * (box[:2] + box[2:])
box_wh = box[2:] - box[:2]
# 再计算重合度较高的先验框的中心与长宽
assigned_priors_center = 0.5 * (assigned_priors[:, :2] +
assigned_priors[:, 2:4])
assigned_priors_wh = (assigned_priors[:, 2:4] -
assigned_priors[:, :2])
# 逆向求取ssd应该有的预测结果
encoded_box[:, :2][assign_mask] = box_center - assigned_priors_center
encoded_box[:, :2][assign_mask] /= assigned_priors_wh
# 除以0.1
encoded_box[:, :2][assign_mask] /= assigned_priors[:, -4:-2]
encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_priors_wh)
# 除以0.2
encoded_box[:, 2:4][assign_mask] /= assigned_priors[:, -2:]
return encoded_box.ravel()
def assign_boxes(self, boxes):
#---------------------------------------------------#
# assignment分为3个部分
# :4 的内容为网络应该有的回归预测结果
# 4:-8 的内容为先验框所对应的种类,默认为背景
# -8 的内容为当前先验框是否包含目标
# -7: 无意义
#---------------------------------------------------#
assignment = np.zeros((self.num_priors, 4 + self.num_classes + 8))
assignment[:, 4] = 1.0
if len(boxes) == 0:
return assignment
# 对每一个真实框都进行iou计算
encoded_boxes = np.apply_along_axis(self.encode_box, 1, boxes[:, :4])
#---------------------------------------------------#
# 在reshape后,获得的encoded_boxes的shape为:
# [num_true_box, num_priors, 4+1]
# 4是编码后的结果,1为iou
#---------------------------------------------------#
encoded_boxes = encoded_boxes.reshape(-1, self.num_priors, 5)
#---------------------------------------------------#
# [num_priors]求取每一个先验框重合度最大的真实框
#---------------------------------------------------#
best_iou = encoded_boxes[:, :, -1].max(axis=0)
best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0)
best_iou_mask = best_iou > 0
best_iou_idx = best_iou_idx[best_iou_mask]
#---------------------------------------------------#
# 计算一共有多少先验框满足需求
#---------------------------------------------------#
assign_num = len(best_iou_idx)
# 将编码后的真实框取出
encoded_boxes = encoded_boxes[:, best_iou_mask, :]
assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx,np.arange(assign_num),:4]
#----------------------------------------------------------#
# 4代表为背景的概率,设定为0,因为这些先验框有对应的物体
#----------------------------------------------------------#
assignment[:, 4][best_iou_mask] = 0
assignment[:, 5:-8][best_iou_mask] = boxes[best_iou_idx, 4:]
#----------------------------------------------------------#
# -8表示先验框是否有对应的物体
#----------------------------------------------------------#
assignment[:, -8][best_iou_mask] = 1
# 通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的
return assignmentloss计算
在loss计算过程中,由于SSD可能导致正负样本的不平衡而增加的训练难度,所以一般在计算loss时,通常取1:3的正负样本比例,同意注意:预测值的前四位是预期位置信息,第五位到倒数第八位是类别信息,后面是先验框的原始位置信息。
class MultiboxLoss(object):
def __init__(self, num_classes, alpha=1.0, neg_pos_ratio=3.0,
background_label_id=0, negatives_for_hard=100.0):
self.num_classes = num_classes
self.alpha = alpha
self.neg_pos_ratio = neg_pos_ratio
if background_label_id != 0:
raise Exception('Only 0 as background label id is supported')
self.background_label_id = background_label_id
self.negatives_for_hard = negatives_for_hard
def _l1_smooth_loss(self, y_true, y_pred):
abs_loss = tf.abs(y_true - y_pred)
sq_loss = 0.5 * (y_true - y_pred)**2
l1_loss = tf.where(tf.less(abs_loss, 1.0), sq_loss, abs_loss - 0.5)
return tf.reduce_sum(l1_loss, -1)
def _softmax_loss(self, y_true, y_pred):
y_pred = tf.maximum(tf.minimum(y_pred, 1 - 1e-15), 1e-15)
softmax_loss = -tf.reduce_sum(y_true * tf.log(y_pred),
axis=-1)
return softmax_loss
def compute_loss(self, y_true, y_pred):
batch_size = tf.shape(y_true)[0]
num_boxes = tf.to_float(tf.shape(y_true)[1])
# 计算所有的loss
# 分类的loss
# batch_size,8732,21 -> batch_size,8732
conf_loss = self._softmax_loss(y_true[:, :, 4:-8],
y_pred[:, :, 4:-8])
# 框的位置的loss
# batch_size,8732,4 -> batch_size,8732
loc_loss = self._l1_smooth_loss(y_true[:, :, :4],
y_pred[:, :, :4])
# 获取所有的正标签的loss
# 每一张图的pos的个数
num_pos = tf.reduce_sum(y_true[:, :, -8], axis=-1)
# 每一张图的pos_loc_loss
pos_loc_loss = tf.reduce_sum(loc_loss * y_true[:, :, -8],
axis=1)
# 每一张图的pos_conf_loss
pos_conf_loss = tf.reduce_sum(conf_loss * y_true[:, :, -8],
axis=1)
# 获取一定的负样本
num_neg = tf.minimum(self.neg_pos_ratio * num_pos,
num_boxes - num_pos)
# 找到了哪些值是大于0的
pos_num_neg_mask = tf.greater(num_neg, 0)
# 获得一个1.0
has_min = tf.to_float(tf.reduce_any(pos_num_neg_mask))
num_neg = tf.concat( axis=0,values=[num_neg,
[(1 - has_min) * self.negatives_for_hard]])
# 求平均每个图片要取多少个负样本
num_neg_batch = tf.reduce_mean(tf.boolean_mask(num_neg,
tf.greater(num_neg, 0)))
num_neg_batch = tf.to_int32(num_neg_batch)
# conf的起始
confs_start = 4 + self.background_label_id + 1
# conf的结束
confs_end = confs_start + self.num_classes - 1
# 找到实际上在该位置不应该有预测结果的框,求他们最大的置信度。
max_confs = tf.reduce_max(y_pred[:, :, confs_start:confs_end],
axis=2)
# 取top_k个置信度,作为负样本
_, indices = tf.nn.top_k(max_confs * (1 - y_true[:, :, -8]),
k=num_neg_batch)
# 找到其在1维上的索引
batch_idx = tf.expand_dims(tf.range(0, batch_size), 1)
batch_idx = tf.tile(batch_idx, (1, num_neg_batch))
full_indices = (tf.reshape(batch_idx, [-1]) * tf.to_int32(num_boxes) +
tf.reshape(indices, [-1]))
neg_conf_loss = tf.gather(tf.reshape(conf_loss, [-1]),
full_indices)
neg_conf_loss = tf.reshape(neg_conf_loss,
[batch_size, num_neg_batch])
neg_conf_loss = tf.reduce_sum(neg_conf_loss, axis=1)
# 求loss总和
total_loss = K.sum(pos_conf_loss + neg_conf_loss)/K.cast(batch_size,K.dtype(pos_conf_loss))
total_loss += K.sum(self.alpha * pos_loc_loss)/K.cast(batch_size,K.dtype(pos_loc_loss))
return total_loss
至此,所有关于SSD的关键部分就讲解完了,后续会陆续更新其他算法。



