推荐系统
简介
在互联网大数据时代下,物品的长尾性和二八原则是非常严重的。具体来说,对于一个平台而言80%的销售额可能是那些最畅销20%的物品。但是那20%的物品其实只能满足一小部分人的需求,对于绝大多数的用户的需求需要从那80%的长尾物品中去满足。虽然长尾物品的总销售额占比不大,但是因为长尾物品的数量及其庞大,如果可以充分挖掘长尾物品,那这些长尾物品的销售额的总量有可能会超过热门商品。
推荐系统解决产品能够最大限度地吸引用户、留存用户、增加用户粘性、提高用户转化率的问题,从而达到平台商业目标增长的目的。不同平台的目标取决于其商业的盈利目的,例如对于YouTube,其商业目标是最大化视频被点击(点击率)以及用户观看的时长(完播率),同时也会最大化内置广告的点击率;对于淘宝等电商平台,除了最大化商品的点击率外,最关键的目标则是最大化用户的转化率,即由点击到完成商品购买的指标。推荐系统能够平台带来丰厚的商业价值 。
推荐系统架构
从系统架构和算法架构两个角度出发解析推荐系统通用架构。
系统架构设计思想是大数据背景下如何有效利用海量和实时数据,将推荐系统按照对数据利用情况和系统响应要求出发,将整个架构分为离线层、近线层、在线层三个模块。然后分析这三个模块分别承担推荐系统什么任务,有什么制约要求。更多的是考虑推荐算法在工程技术实现上的问题,系统架构是如何权衡利弊,如何利用各种技术工具帮助我们达到想要的目的的,方便我们理解为什么推荐系统要这样设计。
算法架构是从我们比较熟悉的召回、粗排、排序、重排等算法环节角度出发的,重要的是要去理解每个环节需要完成的任务,每个环节的评价体系,以及为什么要那么设计。还有一个重要问题是每个环节涉及到的技术栈和主流算法。
系统架构
从数据驱动角度,对于数据,最简单的方法是存下来,留作后续离线处理,离线层就是我们用来管理离线作业的部分架构。在线层能更快地响应最近的事件和用户交互,但必须实时完成。这会限制使用算法的复杂性和处理的数据量。离线计算对于数据数量和算法复杂度限制更少,因为它以批量方式完成,没有很强的时间要求。不过,由于没有及时加入最新的数据,所以很容易过时。近线层介于两种方法之间,可以执行类似于在线计算的方法,但又不必以实时方式完成。
- 离线层:不用实时数据,不提供实时响应;
- 近线层:使用实时数据,不保证实时响应;
- 在线层:使用实时数据,保证实时在线服务;
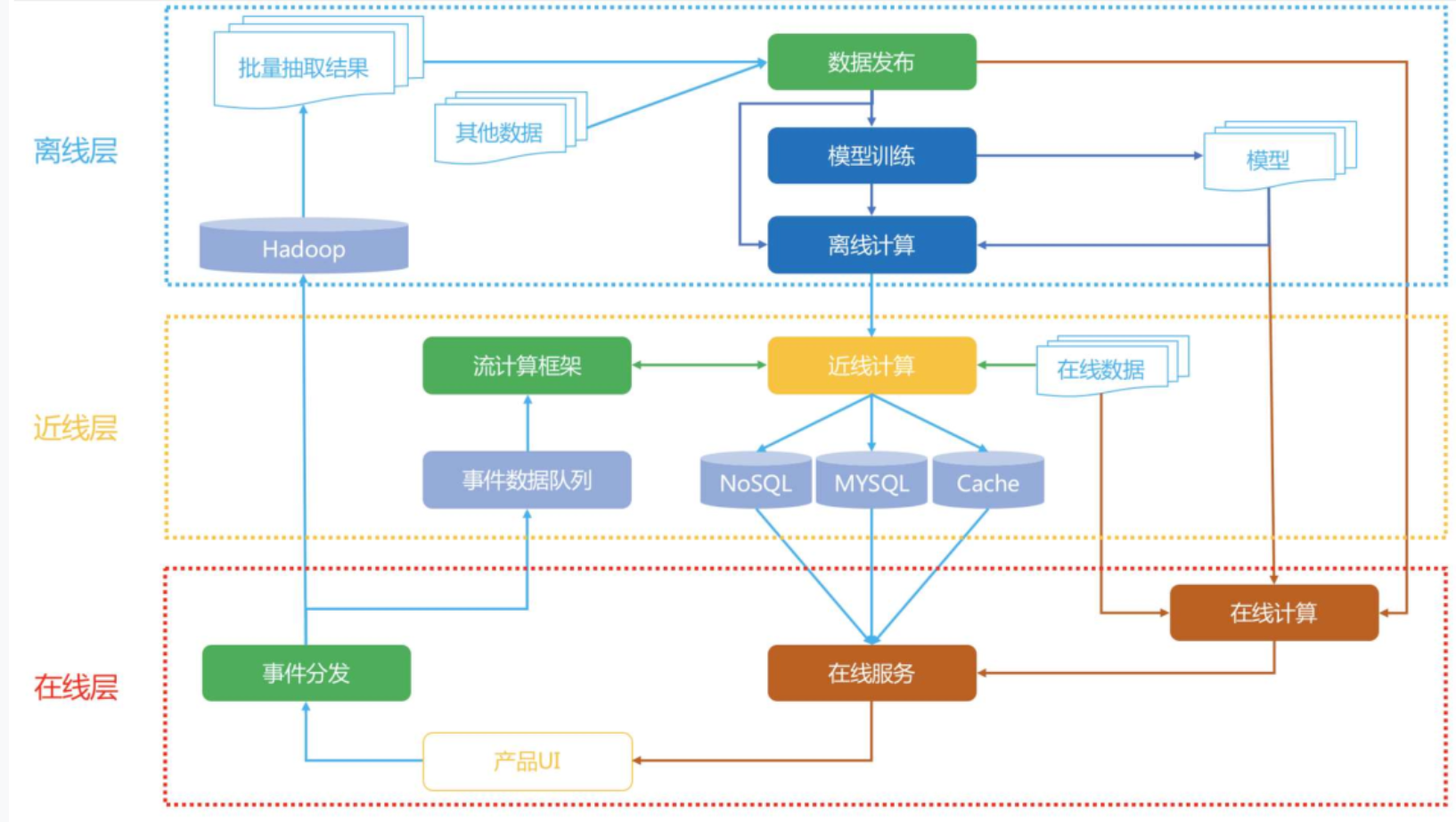
离线层是计算量最大的一个部分,它的特点是不依赖实时数据,也不需要实时提供服务。需要实现的主要功能模块是:数据处理、数据存储;特征工程、离线特征计算;离线模型的训练;面临主要的问题是海量数据存储、大规模特征工程、多机分布式机器学习模型训练。目前主流的做法是HDFS,收集到我们所有的业务数据,通过HIVE等工具,从全量数据中抽取出我们需要的数据,进行相应的加工,离线阶段主流使用的分布式框架一般是Spark。
近线层的主要特点是准实时,它可以获得实时数据,然后快速计算提供服务,但是并不要求它和在线层一样达到几十毫秒这种延时要求。近线层的产生是同时想要弥补离线层和在线层的不足,折中的产物。近线层的发展得益于最近几年大数据技术的发展,很多流处理框架的提出大大促进了近线层的进步。如今Flink、Storm等工具一统天下。
在线层,就是直接面向用户的的那一层了。最大的特点是对响应延时有要求,因为它是直接面对用户群体的。所有的用户请求都会发送到在线层,在线层需要快速返回结果,它主要承担的工作有:
- 模型在线服务:包括了快速召回和排序;
- 在线特征快速处理拼接:根据传入的用户ID和场景,快速读取特征和处理;
- AB实验或者分流:根据不同用户采用不一样的模型,比如冷启动用户和正常服务模型;
- 运筹优化和业务干预:比如要对特殊商家流量扶持、对某些内容限流;
算法架构
召回层的主要目标时从推荐池中选取几千上万的item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。召回主要考虑的内容有:
- 考虑用户层面:用户兴趣的多元化,用户需求与场景的多元化:例如:新闻需求,重大要闻,相关内容沉浸阅读等等
- 考虑系统层面:增强系统的鲁棒性;部分召回失效,其余召回队列兜底不会导致整个召回层失效;排序层失效,召回队列兜底不会导致整个推荐系统失效
- 系统多样性内容分发:图文、视频、小视频;精准、试探、时效一定比例;召回目标的多元化,例如:相关性,沉浸时长,时效性,特色内容等等
- 可解释性推荐一部分召回是有明确推荐理由的:很好的解决产品性数据的引入;
粗排的原因是有时候召回的结果还是太多,精排层速度还是跟不上,所以加入粗排。粗排阶段的架构设计主要是考虑三个方面,一个是根据精排模型中的重要特征,来做候选集的截断,另一部分是有一些召回设计,比如热度或者语义相关的这些结果,仅考虑了item侧的特征,可以用粗排模型来排序跟当前User之间的相关性,据此来做截断,这样是比单独的按照item侧的倒排分数截断得到更加个性化的结果,最后是算法的选型要在在线服务的性能上有保证,因为这个阶段在pipeline中完成从召回到精排的截断工作,在延迟允许的范围内能处理更多的召回候选集理论上与精排效果正相关。
精排层是我们学习推荐入门最常常接触的层,我们所熟悉的算法很大一部分都来自精排层。这一层的任务是获取粗排模块的结果,对候选集进行打分和排序。目前精排层深度学习已经一统天下了,精排阶段采用的方案相对通用,首先一天的样本量是几十亿的级别,我们要解决的是样本规模的问题,尽量多的喂给模型去记忆,另一个方面时效性上,用户的反馈产生的时候,怎么尽快的把新的反馈给到模型里去,学到最新的知识。
重排序阶段对精排生成的Top-N个物品的序列进行重新排序,生成一个Top-K个物品的序列,作为排序系统最后的结果,直接展现给用户。重排序的原因是因为多个物品之间往往是相互影响的,而精排序是根据PointWise得分,容易造成推荐结果同质化严重,有很多冗余信息。而重排序面对的挑战就是海量状态空间如何求解的问题,一般在精排层我们使用AUC作为指标,但是在重排序更多关注NDCG等指标。



