Redis五大基本类型
String
# 移动数据到0号数据库
move key 0
# 查看过期时间
ttl key
# 设置值,NX:当没有值时设置,XX:当有值时设置,get:先返回原来的值然后再重新设置值,ex:设置过期时间second,px:设置过期时间milisecond,exat:设置过期的时间以unix的系统时间准second,pxat:设置过期的时间以unix的系统时间准millisecond,keepttl:如果修改前存在过期时间则使用之前的过期时间
set key value [NX|XX] [get] [ex|px|exat|pxat] [keepttl]
# 获取值
get key
# 设置多个值,要么都成功要么都失败
mset key value [key value...] [NX|XX] [get] [ex|px|exat|pxat] [keepttl]
# 获取多个值
mget key [key...]
#获取指定范围的值
set name lujie
# 结果为:lu
getrange name 0 2
#结果为:qinie
setrange name 0 qin
# 数值增减:必须是数字,加1,减1,加3,减3
incr key
decr key
incrby key 3
decrby key 3
# 获取值长度
strlen key
# 字符串拼接
append key xxxx
# 数据库锁:设置一把锁并设置10秒过期
setex key 10 value
# 如果不存在就设置创建数据,存在则无效
setnx key value
# 先查后改
getset key valueList
# 从左侧添加数据
lpush key value1,value2
#从右侧添加数据
rpush key value1,value2
#从左侧拿出输出
lpop key
#从右侧拿出数据
rpop key
# 从左侧输出范围2-5数据
lrange key 2 5
# 从右侧输出范围2-5数据
rrange key 2 5
# 获取列表中序号对应的数据
lindex key 0
# 获取列表的长度
llen key
# 删除N个值等于v的数据
lrem key N v
# 截图start-end之间的数据
ltrim key start end
# 将列表中的数据移动到另一个列表中
rpoplpush source target
# 给列表某个位置改为另一个值
lset key index value
#在V数据之前或之后插入K
linsert key before/after v k
Hash
# 设置值:hset user01 name lujie age 27 sex nan
hset key field value
# 获取某个属性
hget key field
#获取所有属性
hgetall key
# 修改多个属性-弃用
hmset key field value
# 获取多个属性
hmget key field1 field2...
#获取有多少个属性
hlen key
# 删除某个或多个属性
hdel key field ...
# 判断key中是否存在某个属性
hexists key field
# 获取所有的属性
hkeys key
# 获取所有属性的值
hval key
# 给整形数值加上number
hincrby key field number
# 给浮点数加上number
hincrbyfloat key field number
# 不存在则赋值,存在了就无效
hsetnx key field valueset
#添加多个元素
sadd key value...
# 遍历所有元素
smembers key
# 判断是否存在某个元素
sismember key value
#删除某个元素
srem key value
# 获取元素个数
scard key
# 随机拿出N个数据
srandmember key N
#随机拿出N个数据并删除
spop key N
# 将key1中的value移动到key2中
smove key1 key2 value
# 取出在set1中的元素同时不存在set2中的数据
sdiff set1 set2
# 取set1与set2的并集
sunion set1 set2
# 取set1和set2的交集
sinter set1 set2
# 判断set1和set2有多少个交集,limit决定返回值不能大于num,一般用于保证性能
sintercard number_sets set1 set2 [limit num]Zset
#添加元素,根据分数排序
zadd key score value[score1 value1...]
#正序后反序返回序号在范围内的数据
zrange/zrevrange key start stop [withscores]
# 获取值对应的分数
zscore key value
# 获取集合中的数量
zcard key
# 删除分数为N的数据
zrem key N
hyperlogLog
# 添加6个不重复的元素
pfadd h01 1 2 3 4 5 6
# 添加含有重复的元素,只会保存4个
pfadd h02 1 2 3 3 4 4
# 统计基数数量,即不重复的数据
pfcount h02
# 将h01和h02合并为一个
pfmerge h03 h01 h02 [...]
# 输出h03
pfcount h03GEO
# 添加坐标
geoadd key x y name x1 y1 name2
# 返回位置
geopos key name1...
# 实际key是一个zset类型,经纬度作为分数排序
# 获取坐标的hash
geohash key name1
# 获取两个位置之间的距离
geodist key name1 name2
# 以x,y为中心,radius半径查询附加的东西,带出距离,经纬度
georadius key x y radius withdist withcoord count 10 descBitmap
# 给key的第offset位赋值val
setbit key offset val
getbit key offset
bitcount kye start end
bitop operation destkey key
Redis初级
持久化
- AOF和RDB可以同时开启,启动时优先加载AOF数据,没有AOF则加载RDB文件。一般RDB用于备份数据库
AOF
AOF持久化策略时通过缓冲区记录所有更新数据的操作,当达到一定的阈值后将缓冲区的数据写入AOF文件中,随着AOF文件的不断膨胀,Redis还会将AOF文件进行压缩,当服务器重启时会将AOF文件中的所有命令重新加载到服务其中运行。
缓冲区数据写入AOF文件的三种写入策略,在redis.conf配置文件中表现为
appendfsync everysec- Always:每当有更新命令出现在缓存中,就立即写入AOF文件中
- everysec(默认的写入策略):先把命令写入缓存中,然后每隔一秒后将缓冲区数据写入AOF文件
- no:将命令写入缓冲区后,redis服务不决定何时写入AOF文件,而是交由操作系统进行判断何时写入AOF
Redis默认不开启AOF数据持久化,需要在redis.conf文件中手动启用:
appendonly yes,然后配置上述的写入策略,然后保存的文件路径在redis6中与RDB的保存路径一致,redis7中根据appenddirname xxx配置在RDB的路径下再创建一个xxx文件夹进行保存数据,文件名称根据配置appendfilename xxx进行命名。注意redis6之前AOF文件只有一个完成的文件,redis7后将一个文件拆分为3个文件进行数据保存:- 基本文件base,用于保存最基本的数据(应该是将增量文件中的命令数据保存而来,日志重写相关)
- 增量文件,根据数据量可能有多个增量文件,用于保存再基本文件的基础上的增量数据
- 清单文件,由于基本文件和增量文件数量较多,为了便于管理所以新增一个清单文件
AOF文件异常恢复命令,如果文件损坏,可以通过redis-check-aof –fix命令进行修复
AOF缺点:由于AOF保存的是命令,因此文件会很大,且异常恢复也会较为缓慢
AOF优点:数据一致性较高,可靠性强
日志重写:随着AOF文件一直变大,当超过一定的阈值时,redis会将命令重新写为恢复数据的最终日志文件,也可以通过
bgrewriteaof命令进行手动触发- 重写的过程,首先启动子进程将AOF文件复制一份临时文件用于进行重写压缩,主进程将后续的写命令一边保存再内存中,一边写入旧的AOF文件中(保证可用),当子进程完成后,主进程将内存中的命令写入新的AOF文件中,然后用新的AOF文件代替旧的AOF文件。
RDB
- RDB即Redis Database,Redis数据库文件,通常为当前redis数据库的快照文件,可以用于快速恢复数据。
- 配置文件中
save ""可以禁用RDB,但是仍然可以通过save/bgsave进行备份 - 优点:
- 适合大规模的数据恢复,速度快
- 按照业务定时备份
- 对数据的完整性和一致性要求不高
- 缺点:
- 由于是全量备份所以数据量会影响系统性能
- 备份与备份之间的数据容易丢失
- 哪些操作会产生RDB?
- 定时备份的配置,每隔一段时间都是生成RDB
- 手动触发备份:SAVE/BGSAVE
- Flushall
- shutdown执行且没有开启AOF
- 主从复制时,主节点自动触发
事务
- Redis单线程所以事务不存在隔离级别,无法保证原子性,如果执行到一半失败了,无法回滚,单线程再执行一个事务中不会再执行其他命令
- Redis执行事务之前如果语法检测有问题,那么不会执行,如果语法检测没有问题,但是执行过程中发生错误,那么不会回滚,错误的执行失败,成功的执行成功。
- Redis提供了watch来实现乐观锁的机制,在执行事务之前对key进行watch,在执行事务的时候就会检查这个key是否被更改过类似于CAS。当运行exec命令之后或者断开连接,所有的watch都会被取消
# multi命令相当于mysql begin,开启事务
multi
cmd 1
cmd 2
cmd3
# exec 相当于myql end,结束事务。
exec常用命令
- discard
- exec
- multi
- unwatch
- watch key [key …]
事务执行示例
- 正常执行
multi xxx exec- 放弃事务
multi xxx discard- watch监控
watch key1 multi xxx exec
管道
针对频繁的单一命令操作可以通过管道进行处理,提高性能
- 使用方法:通过将多条命令记录到文本中,通过redis提供的–pipeline参数进行输入服务器
- 对比原生命令(mset/mget),原生命令是原子性,管道是非原子性,原生命令一次只能执行一种类型的命令,管道可以执行不同类型的命令,原生命令只依赖服务器,管道需要服务器和客户端一起
- 对比事务:事务具有原子性,管道不具有原子性,管道是一次性发送所有命令,事务以一条一条发,直到exec发送完,事务执行时会阻塞其他命令,但是管道不会
发布订阅
- subscribe channel [channel…] :订阅多个频道的消息
- publish channel message :向chnnel频道发布消息
- psubscribe pattern [pattern…]:订阅消息使用通配符
- pubsub channels:查看所有的频道列表
- pubsub numsub [channel…] :查看某个频道有几个订阅者
- pubsub numpat :查看使用通配符的频道数量
- unsubscribe [channel…]:取消订阅
主从复制
- info replication:查看当前的主从结构
- slaveof no one:断开主从连接,变为主机
- slaveof ip port:成为另一个IP的从机(旧版命令)
- replicaof ip port:成为IP的从机(新版命令)
- 主机同步数据的密码配置:
requirepass 111111 - 主机挂掉,从机不会成为主机。从机第一次连接会全量复制(通过RDB复制,复制期间新增的数据会通过命令和RDB文件一起发送过去),如果从机原来有数据则会被覆盖清除,后续主机会根据配置中时间间隔,每隔一段时间发送心跳确认从机是否存在,后续增量复制,从机挂掉之后重新连接,会从挂掉之前的offerset开始进行同步,从机可以连接从机,但是网络延迟就会增加
- 缺点:从机连接从机,复制延迟,如果主机挂了,从机不会成为主机。
- 主机接收到写命令后,在写入数据的同时会将命令写入复制缓冲区(不是复制积压缓冲区),然后复制缓冲区会发送给从机,同时将命令写入复制积压缓冲区,用于如果从机断开后重连情况下的增量同步
哨兵监控
当主机宕机后,从机无法成为主机导致无法进行写命令,此时通过哨兵监控集群状态,可以将从机切换为主机。如果没有redis集群的情况下,通过哨兵监控是一种实现高可用的有效方式
所谓的哨兵其实也是redis服务,只是启动命令和配置文件不一样,可以在同一台机器上同时启动redis和哨兵服务,当然这只是自己平时学习可以使用。
当主机宕机后,哨兵集群会进行投票选举一个领导者作为发起主从切换的人。投票选举的过程是Raft算法,当一个哨兵向另一个哨兵发起申请,如果另一个哨兵没有同意别人,那么就给第一个哨兵投票。领导者选举完成之后,领导者会选择一个从机作为主机,规则:先看优先级(自己再配置文件中配置,数字越小优先级越高),一样则看复制的偏移量,一样则看runid(小则主)。选举完成之后,新主机执行slaveof no one完成成为主机操作,其他从机执行slaveof成为新主机的从机
哨兵的配置文件大致如下:
#cd 至redis的安装目录
cd /usr/local/redis-6.0.10
#创建哨兵的工作目录
mkdir -p /usr/local/redis-6.0.10/redis-sentinel-working
#可自行vi命令编辑 sentinel_conf
#配置哨兵的工作目录
sed -i "s/^dir .*/dir /usr/local/redis-6.0.10/redis-sentinel-working /" sentinel_conf
#配置哨兵的日志文件
sed -i "s/^logfile .*/logfile /usr/local/redis-6.0.10/redis-sentinel.log /" sentinel_conf
#配置哨兵的端口号 配置文件中默认就是26379
sed -i "s/^port .*/port 26379 /" sentinel_conf
#设置主节点ip 端口 mymaster 192.168.195.59 6379 2
sed -i "s/^sentinel monitor .*/sentinel monitor mymaster 192.168.195.59 6379 2 /" sentinel_conf
#设置redis访问密码
sed -i "/^sentinel monitor .*/a\\ \n\\sentinel auth-pass mymaster Test2024" sentinel_conf- 其中需要重点了解的配置
#当在Redis实例中开启了requirepass foobared 授权密码这样所有连接kedis实例的客户端都要提供密码
#设置哨兵sentinel连接主从的密码注意必须为主从设置- - 样的验证密码
# sentine1 auth-pass
sentine1 auth-pass mymaster MySUPER--secret-0123passwOrd
#指定多少毫秒之后主节点没有应答哨兵sentine1 此时哨兵主观上认为主节点下线默认30秒
# sentinel down-after-mi 11i seconds
sentine1 down-after-milliseconds mymaster 30000
#这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成fai lover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而 不可用。可以通过将这个值设为1来保证每次只有一个slave处于不能处理命令请求的状态。
# sentine1 paralle1-syncs
sentine1 paralle1-syncs mymaster 1
#故障转移的超时时间failover-timeout 可以用在以下这些方面:
#1.同一个sentine1对同一 个master两次fai lover之间的间隔时间。
#2.当一个slave从一 个错误的master那里同步数据开始计算时间。直到s1ave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有s1aves指向新的master所需的最大时间。不过,即使过了这个超时,slaves 依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
#默认三分钟
# sentine1 failover-timeout
sentine1 fai lover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被-一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentine1有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等 方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,一 个是事件的类型,一个是事件的描述。如果sentine1. conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentine1无法正常启动成功。
#通知脚本
# she11编程
# sentine1 notification-script
sentine1 notification-script mymaster /var/redis/notify. sh
#客户端重新配置主节点参数脚本
#当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
#以下参数将会在调用脚本时传给脚本:
#
#目前总是“failover",
# 是“Teader"或者"observer"中的-一个。
#参数from-ip, from-port, to-ip,to-port是用来和旧的master和新的master(即旧的s lave)通信的
#这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentine1 client-reconfig-script
sentine1 client-reconfig-script mymaster /var/redis/reconfig.sh #一般都是由运维来配置!
启动命令:
redis-sentinel ./redis-sentinel.conf哨兵选举算法Raft算法
Raft算法是一种基于领导者的一致性算法,它要求集群中的每个节点都有三种角色:领导者(leader)、候选者(candidate)和跟随者(follower)。领导者负责发起选举请求,候选者负责投票,跟随者负责响应领导者的指令。Raft算法的核心是选举过程,分为以下几个步骤:
- 初始化:集群启动时,所有的节点都是跟随者,没有领导者。每个节点都有一个
选举超时时间,随机在150ms到300ms之间,如果在超时时间内没有收到领导者的心跳包,就会转变为候选者,开始发起选举。 - 发起选举:候选者会增加自己的选举轮次(term),并向其他节点发送选举请求,包含自己的选举轮次和标识。同时,候选者会给自己投一票,并重置自己的选举超时时间。
- 投票:跟随者收到选举请求后,会比较自己的选举轮次和候选者的选举轮次,如果自己的选举轮次更大,或者已经给其他候选者投过票,就会拒绝投票;否则,就会同意投票,并重置自己的选举超时时间。
- 统计票数:候选者收到投票回复后,会统计自己的票数,如果超过半数,就会成为领导者,并向其他节点发送心跳包,通知自己的领导地位;如果没有超过半数,就会继续等待投票回复,直到超时或者收到心跳包。
- 维持领导者:领导者会周期性地向所有跟随者发送心跳包,维持自己的领导地位,并检查跟随者的状态。如果领导者发现自己的选举轮次小于某个跟随者的选举轮次,就会认为自己的领导地位已经过期,转变为跟随者,重新开始选举超时计时。(如果掉线重新就有可能成为跟随者)
- 处理冲突:如果集群中出现网络分区或者节点故障,可能会导致多个候选者同时发起选举,造成选举冲突。Raft算法通过随机化选举超时时间,使得冲突的概率降低。同时,如果一个候选者收到了另一个候选者的选举请求,它会拒绝投票,并重置自己的选举超时时间。
- 最终,只有一个候选者能够获得多数的票数,成为领导者,结束选举。
集群模式
- 哨兵模式虽然提供了故障转移,但是再选举期间无法提供写入操作,因此集群模式的出现提供了多主多从的模式,实现高可用。
- redis集群是AP,不保证强一致性,有些情况下会丢失丢掉一些系统收到的某些命令,如果主机收到命令写入数据,写完但还未来得及同步挂掉了,那数据就没了
确定数据落点的算法
哈希槽分区算法
槽位:是一个逻辑概念,redis规定有16384个槽位,根据CRC16算法对key进行运算然后mod 16384,得到一个数字,这个数字再0-16384之间,集群根据节点数量等分16384个槽位,每个节点负责一段槽位,根据CRC16运算的结果决定将命令发给哪个节点运行。
分片:每个redis节点就是一个分片。
优点:方便扩容,缩容
为什么是16483个,首先CRC16算法计算得到的是16bit的数据,所以mod的数字最大65535,如果是65535考虑到每次心跳都会包含完整插槽信息,也就有65535/8/1024=8kb的数据量,太多了,如果是16384/8/1024=2kb刚好,同时由于考虑数据同步网络延迟,一般节点数量都不超过1000,所以16384也够用,其次插槽一般通过bitmap进行数据传输,插槽的数量越少,在节点少的情况下压缩效率越高
hash算法
直接通过hash(key) mod 节点数量,这样有点就是简单方便,但是缺点就是一旦宕机扩容等情况发生则数据全部打乱
一致性hash算法,将0-2^31作为一个首位相连的圈坐标,通过一致性hash计算得到0-2^31之间的值,然后顺时针找到最近的一个redis节点,作为数据落点
优点:极大程度避免的数据全部重新洗牌,缺点:如果节点ip通过一致性hash计算后分布不均,会导致数据倾斜,特别是在节点数量较少的情况下。
常用命令
查看集群节点主从关系信息:cluster nodes
查看集群信息:cluster info
进入服务端查看节点信息:info replication
查看某个key属于哪个槽位:cluster keyslot k1
将从机转为主机:cluster failover
查看某个槽位是否已经被占用:cluter countkeysinslot 1207
集群配置完成后,在服务端进行写入操作后,如果计算后的落点不在本服务器会提示你去其他服务器进行写入。为了避免这种情况,在客户端连接到服务端的命令中加上-c参数可以自动路由到对应的服务器。
集群搭建
- 配置文件,一下给出配置文件常用配置,通过
redis-server xxx.conf命令进行启动
# 修改为后台启动
daemonize yes
# 修改端口号
port 8001
# 指定数据文件存储位置
dir /usr/local/redis-app/8001/
# 开启集群模式
cluster-enabled yes
# 集群节点信息文件配置
cluster-config-file nodes-8001.conf
# 集群节点超时间
cluster-node-timeout 15000
# 去掉bind绑定地址
# bind 127.0.0.1 -::1 (这里没写错就是家#注释掉bind配置)
# 关闭保护模式
protected-mode no
# 开启aof模式持久化
appendonly yes
# 设置连接Redis需要密码123(选配)
requirepass 123456
# 设置Redis节点与节点之间访问需要密码123(选配)
masterauth 123456
- 启动完成后,随便找个节点运行一下命令即可实现集群搭建
# -a 密码认证,若没写密码无效带这个参数
# --cluster create 创建集群实例列表 IP:PORT IP:PORT IP:PORT
# --cluster-replicas 复制因子1(即每个主节点需1个从节点)
./bin/redis-cli -a 123456 --cluster create --cluster-replicas 1 192.168.100.101:8001 192.168.100.101:8002 192.168.100.102:8003 192.168.100.102:8004 192.168.100.103:8005 192.168.100.103:8006
Redis集群选举原理
- 当slave节点发现自己的master节点变为FAIL状态时,便尝试进行Failover(故障转移),以期成为新的master。由于挂掉的master节点可能会有多个slave节点,从而存在多个slave节点竞争成为master节点的过程。
- slave节点发现自己的master节点变为FAIL状态
- 将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST(会携带有currentEpoch)信息
- 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch(纪元)只发送一次ACK
- 尝试Failover的slave收集master返回的FAILOVER_AUTH_ACK
- slave收到超过半数master的ACK后变成新Master(这里解释了集群为什么至少需要三个主节点,如果只有两个,当其中一个挂了,只剩一个主节点是不能选举成功的)
- slave广播Pong消息通知其他集群节点
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票
- 延迟计算公式:DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
- SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)。
集群脑裂问题
redis集群没有过半机制会有脑裂问题,网络抖动导致脑裂后多个主节点对外提供写服务,一旦网络环境问题恢复,会将其中一个主节点变为从节点,然后从节点会从主节点进行全量数据复制,这时主节点变成从节点前的所有数据丢失。场景:一台主机没有挂,但是网络抖动导致所有人都认为挂了,于是重新进行选举,导致出现两台主机,当网络恢复,其中原来的主机由于currentepoch较小直接变为从机,这会导致这台机器中从发生网络抖动到重新恢复之间收到的数据直接被覆盖,重新同步。可以通过过半同步配置进行避免,但是如果主机没有从节点那就无法使用。
集群扩容
- 扩容命令
# 使用如下命令即可添加节点将一个新的节点添加到集群中
# -a 密码认证(没有密码不用带此参数)
# --cluster add-node 添加节点 新节点IP:新节点端口 任意存活节点IP:任意存活节点端口
./bin/redis-cli -a 123456 --cluster add-node 192.168.100.104:8007 192.168.100.101:8001
# 使用如下命令将其它主节点的分片迁移到当前节点中
# -a 密码认证(没有密码不用带此参数)
# --cluster reshard 槽位迁移 从节点IP:节点端口,中迁移槽位到当前节点中
./bin/redis-cli --cluster reshard 192.168.100.101:8002
# 通过以上命令将新的主机加入了集群,后续添加从节点
# 使用如下命令即可添加节点将一个新的节点添加到集群中
# -a 密码认证(没有密码不用带此参数)
# --cluster add-node 添加节点 新节点IP:新节点端口 任意存活节点IP:任意存活节点端口
./bin/redis-cli -a 123456 --cluster add-node 192.168.100.104:8008 192.168.100.101:8001
# 连接需设为从节点的Redis服务
./bin/redis-cli -a 123456 -p 8008
# 将当前节点分配为 8cf44439390dc9412813ad27c43858a6bb53365c 的从节点
CLUSTER REPLICATE 8cf44439390dc9412813ad27c43858a6bb53365c
- 缩容命令
# 首先迁移槽位
# -a 密码认证(没有密码不用带此参数)
# --cluster reshard 槽位迁移 从节点IP:节点端口,中迁移槽位到xxx节点中
./bin/redis-cli --cluster reshard 192.168.100.101:8002
# 执行如下命令删除节点
# -a 密码认证(没有密码不用带此参数)
# --cluster del-node 连接任意一个存活的节点IP:连接任意一个存活的节点端口 要删除节点ID
./bin/redis-cli -a 123456 --cluster del-node 192.168.100.101:8002 8cf44439390dc9412813ad27c43858a6bb53365c
Spring集成Redis
jredis
- pom依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>最新版本号</version>
</dependency>- 代码示例
Jedis jedis = new Jedis("IP","PORT");
jedis.auth("PASSWORD");
jedis.set();
jedis.lpush();
...Lettuce
- pom依赖
<!-- Lettuce -->
<dependency>
<groupId>io.lettuce.core</groupId>
<artifactId>lettuce-core</artifactId>
<version>6.1.5.RELEASE</version>
</dependency>- 代码示例
import io.lettuce.core.RedisClient;
import io.lettuce.core.api.StatefulRedisConnection;
import io.lettuce.core.api.sync.RedisCommands;
public class LettuceExample {
public static void main(String[] args) {
// 连接到本地的 Redis 服务
RedisURI redisuri = RedisURI.Builder.redis("IP").withPort(6379).withPassword("123456").build();
RedisClient client = RedisClient.create(redisuri);
StatefulRedisConnection<String, String> connection = client.connect();
// 同步操作
RedisCommands<String, String> syncCommands = connection.sync();
// 设置 key-value
syncCommands.set("key", "value");
// 获取 key 对应的 value
String value = syncCommands.get("key");
System.out.println("key 对应的 value: " + value);
// 关闭连接
connection.close();
client.shutdown();
}
}
RedisTemplate
- pom依赖(spring自动集成lettuce,如果要使用jedis,需要手动排除lettuce)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>spring:
redis:
host: localhost
port: 6379
password: 123456
lettuce:
pool:
max-active: 50
max-idle: 20
max-wait: 10000ms
shutdown-timeout: 500ms
# 集群节点配置
spring:
redis:
cluster:
# 最大重试次数
max-redirects: 3
nodes:
- 127.0.0.1:6379
- 127.0.0.1:6380
- 127.0.0.1:6381
database: 0
timeout: 5000
password: yourpassword
# 动态刷新spring2.3版本之后可以只用,之前的版本可以自己手动配置一下
spring:
redis:
lettuce:
cluster:
refresh:
adaptive: true
period: 30000 # 30秒自动刷新一次- 代码示例
// 默认redis配置的系列化是null,spring自动使用jdk的序列化,导致redis存储数据会存在问题,需要自己配置序列化或者直接使用StringRedisTemplate
@Autowired
private StringRedisTemplate redisTemplate;
public void saveString(String key, String value) {
ValueOperations<String, String> ops = redisTemplate.opsForValue();
ops.set(key, value);
}
public String readString(String key) {
ValueOperations<String, String> ops = redisTemplate.opsForValue();
return ops.get(key);
}
public void saveObject(String key, Object value) {
redisTemplate.opsForValue().set(key, value);
}
public Object readObject(String key) {
return redisTemplate.opsForValue().get(key);
}
public void saveHash(String hashKey, String key, String value) {
HashOperations<String, String, String> hashOps = redisTemplate.opsForHash();
hashOps.put(hashKey, key, value);
}
public String readHash(String hashKey, String key) {
HashOperations<String, String, String> hashOps = redisTemplate.opsForHash();
return hashOps.get(hashKey, key);
}
public void addToList(String key, String value) {
ListOperations<String, String> listOps = redisTemplate.opsForList();
listOps.rightPush(key, value);
}
public List<String> readList(String key) {
ListOperations<String, String> listOps = redisTemplate.opsForList();
return listOps.range(key, 0, -1);
}
public void addToZSet(String key, String value, double score) {
ZSetOperations<String, String> zSetOps = redisTemplate.opsForZSet();
zSetOps.add(key, value, score);
}
public Set<String> readZSet(String key) {
ZSetOperations<String, String> zSetOps = redisTemplate.opsForZSet();
return zSetOps.range(key, 0, -1);
}
Redis高级
单线程&多线程
- redis4.x之后开始支持多线程,所谓的多线程,其中执行命令还是单线程,但是删除,数据同步,备份等操作是多线程,以及客户端的IO连接也是多线程处理
- 为啥快:1.内存操作,2.单线程无需切换上下文,3.多路复用IO,4.数据结构简单
- 单线程优点:1.操作快,2。无需切换上下文,3.瓶颈不在cpu,而是网络和内存
- 单线程缺点:1.删除大key缓慢,
BigKey
- keys */flushdb等操作命令,由于redis是单线程,所以耗时命令一般禁止使用,可以通过redis.conf文件中进行配置禁用
- scan命令可以用于替换keys命令:
scan 0[cursor] match k*[pattern] 10[count] - 所谓的BigKey指的是value,不是key,string类型一般不要超过10KB,hash,list,set等不要超过5000个,非字符串的数据不要用del删除,同时不要对bigkey设置自动过期时间
- bigkey的缺点:内存不均,超时删除,网络请求阻塞
- 如何产生?粉丝数量逐渐增加。如何发现?
redis-cli --bigkey -p -h -a,此命令会给出每个类型的最大的数据相关信息,memery usage key,用于输出key所占的空间 - 如何删除bigkey,采用渐进式删除,先通过scan命令查询数据,然后删除,不断减少列表数据量,最后删除完成。
- 如何调优?采用非阻塞删除命令:unlink,flushall/flushdb async,或者通过conf配置文件启用惰性删除。其中unlink是主动惰性删除,通过评估删除时间决定是否采用惰性删除,unlink命令对应的key会立即删除,value会异步删除。,被动惰性删除指的是通过conf文件配置后,del命令删除时会根据配置进行判断是否惰性删除。
- 惰性删除:惰性删除是一种删除策略,就是在删除时只删除key和value的关系,而value交给异步线程去处理,只要涉及删除的地方都可以使用惰性删除的原理,因此惰性删除在配置文件中有多种配置:
- lazyfree-lazy-eviction:当 redis 内存达到阈值 maxmemory 时,将执行内存淘汰
- lazyfree-lazy-expire:当设置了过期 key 的过期时间到了,将删除 key
- lazyfree-lazy-server-del:这种主要用户提交 del 删除指令
- replica-lazy-flush:主要用于复制过程中,全量同步的场景,从节点需要删除整个 db
- 过期的数据如何删除?
- 请求删除:如果一条数据逻辑已经被删除了,那么当再次被访问时则立即删除,这种策略下出现很多过期的key没有被删除
- 定期删除:为了释放空间,采用定期删除方式处理,但是又出现大key删除慢且卡顿
- 异步删除:将大key交给layz-free异步线程处理
缓存双写一致性更新策略
外部请求为查询的情况下会出现:双检加锁
- 外部请求数据流程
- 首先查询redis,如果有则直接返回,如果没有走下一步
- 防止高并发,直接synchronize同步锁,在同步块中,再查询一次redis,如果有则返回,如果没有则查询数据库
- 查询完数据库后,写回redis
外部请求为更新操作时:如何保证redis和mysql数据最终一致性
- 给缓存设置过期时间,并定期写回时保证最终一致性的方案
- 更新操作数据应当以数据库mysql为准,保证数据要准确写入mysql
- 四种更新策略:1.先更新数据库再更新缓存,2.先更新缓存再更新数据库,3.先删除缓存再更新数据库,4.先更新数据库再删除缓存
- 1.第一种和第二中在多线程情况下,会导致一段时间的数据不一致性,线程a更新mysql后,b线程更新mysql,b线程更新redis,a线程更新redis。最终导致mysql中数据来源与b,redis数据来源于a。
- 2.第三种情况,线程a先删除缓存,b线程过来查询又将数据库中的数据读取出来放到redis中,a更新完后,之后就不一致了,解决方法:延时双删,a线程更新前删除一边,更新完成之后,睡眠一段时间再删除一次,因为b线程可能查询完成之后,阻塞一段时间再重新写入redis。如果a线程不想阻塞,可以通过异步线程进行操作。
- 3.a线程先更新数据库,然后b线程读取到旧值,a线程再删除缓存,这样只有b线程一段时间读取到旧值(如果要强一致性,那就只能加锁了)
- 最终解决方案:先更新数据库,然后异步订阅binlog消息,接收到数据库变动之后将要删除的键值对暂存到消息队列中,然后尝试删除缓存,删除成功则去掉消息队列中的数据,否则从消息队列中获取数据重复尝试。
案例实战
在企业中实际使用的方案一般都是第四种方案,先更新mysql,然后更新redis缓存。主要通过cannal对mysql的binlog日志进行监听,将更新的数据同步到redis。cannal其实就是模拟一个从机连接到主机mysql上,mysql自动会将更新的binlog同步给从机。
- cannal主要用途是基于数据库增量日志解析,提供增量数据订阅和消费。主要包括:数据库镜像,数据库实时备份,索引构建和实时维护,业务cache刷新,带业务逻辑的增量数据处理。
- cannal工作原理:1.cannal模拟mysql从机的交互协议,伪装自己为MySQL从机,向主机发送dump协议,主机接收到dump请求后开始将binlog日志推送给从机,cannal解析binlog对象。
按照主从配置流程将主机配置好,下载cannal,安装完成后,配置mysql的地址到instance.properties并且将mysql的cannal账户配置到cannal.instance.dbUsername/dbPassword。启动cannal即可。
- 配置完成对应的cannal后,代码实战可以参考官网给出的案例。
Bitmap/hyperloglog/Geo数据实战
常见数据统计类型:聚合统计,排序统计,二值统计,基数统计
- 聚合统计:主要用于不同集合之间的交差并集合统计(set结构)
- 排序统计:主要用户评论展示,一般按照时间排序和分页展示(zset结构排序)
- 二值统计:集合中只用01来表示数据,通常用于打卡签到(bitmap)
- 基数统计:所谓基数就是集合中不重复的数据(hyperLoglog)
UV :unique vistor(独立访客),需要去重
PV :page vistor(页面浏览量)
DAU :daily active user(日活跃用户数量),需要去重
MAU: mouth active user(月活跃用户数量)
hyperloglog:用于去重统计,通过pfadd命令添加元素,如果这个元素没有则添加成功返回1,如果已经存在则返回0。原理:通过hash函数计算得到64位字节,前14位用于确定桶位置,后50位从低位往高位计算连续0的个数,作为判断是否重复的精度。准确率在0.81%左右,如果需要更高的精度,可以采用多个hyperloglog进行合并,通过pfmerge命令合并多个hyperloglog,合并后的hyperloglog的精度是合并前的精度乘以合并前的数量。
GEO:用于存储地理位置,通过redis提供的命令可以计算不同地点之间的距离,查询附近的地点,计算距离等操作
bitmap:用于计算签到,打卡等相关需求是用到的数据接口,每个bit只表示是否两种状态,数据存储量少。
布隆过滤器BoomFilter
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的,是一种非常节省空间的概率数据结构,运行速度快,占用内存小,但是有一定的误判率且无法删除元素。它实际上是一个很长的二进制向量和一系列随机映射函数组成,主要用于判断一个元素是否在一个集合中。
- 布隆过滤器的优点:
- 支持海量数据场景下高效判断元素是否存在
- 布隆过滤器存储空间小,并且节省空间,不存储数据本身,仅存储hash结果取模运算后的位标记
- 不存储数据本身,比较适合某些保密场景
- 布隆过滤器的缺点:
- 不存储数据本身,所以只能添加但不可删除,因为删掉元素会导致误判率增加
- 由于存在hash碰撞,匹配结果如果是“存在于过滤器中”,实际不一定存在
- 当容量快满时,hash碰撞的概率变大,插入、查询的错误率也就随之增加了
布隆过滤器可以结合bitmap进行使用,从而实现相关业务需求。
- 数据库防止穿库,Google Bigtable,HBase 和 Cassandra 以及 Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会大大提高数据库查询操作的性能
- 判断用户是否阅读过某一个视频或者文章,类似抖音,刷过的视频往下滑动不再刷到,可能会导致一定的误判,但不会让用户看到重复的内容
- 网页爬虫对URL去重,采用布隆过滤器来对已经爬取过的URL进行存储,这样在进行下一次爬取的时候就可以判断出这个URL是否爬取过了
- 使用布隆过滤器来做黑名单过滤,针对不同的用户是否存入白名单或者黑名单,虽然有一定的误判,但是在一定程度上还是很好的解决问题
- 缓存击穿场景,一般判断用户是否在缓存中,如果存在则直接返回结果,不存在则查询数据库,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查询到则穿透到数据库查询。如果不在布隆过滤器中,则直接返回,会造成一定程度的误判
- WEB拦截器,如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中。可以提高缓存命中率。Squid 网页代理缓存服务器在 cache digests 中就使用了布隆过滤器。Google Chrome浏览器使用了布隆过滤器加速安全浏览服务
缓存预热/雪崩/击穿/穿透
- 缓存预热
- 缓存雪崩:同一时间,同时过期
- 过期时间随机设置
- 双检加锁
- 缓存续期
- 缓存击穿:同一时间大量请求,且缓存刚好过期的情况下,访问数据库
- 热点数据自动续期
- 加锁处理,双检加锁
- 缓存穿透:查询的key在数据库中不存在,导致redis中不可能存在对应的缓存,因此每次都查询数据库
- 通过布隆过滤器进行处理,将所有可能被查询的key都放置在布隆过滤器中
- 将空值也作为数据存放在redis
- 对接口查询参数进行校验
分布式锁
分布式锁的特点:独占性,高可用,防死锁,不乱抢,重入性
setnx+过期时间实现分布式锁,
redis手动实现分布式锁过程:
- 创建一个共同key和唯一的value通过setnx命令保存到redis中
- 如果保存失败则while循环等待重复创建
- 如果成功则进行业务操作
- 完成业务操作后查询key的value是否是自己的value,如果是则删除,不是则返回(删除过程结合lua脚本,避免非原子操作的删除)
- lua脚本官网结合案例学习即可
代码示例
@Service
public class UserServiceImpl implements UserService {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String port;
@Override
public String userInfoHandler() {
String retMessage = "";
String key = "redislock";
String uuidvalue = UUID.randomUUID().toString();
while(!stringRedisTemplate.opsForValue().setIfAbsent(key,uuidvalue, 10, TimeUnit.SECONDS)){
try {
Thread.sleep(200);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
try{
String result = stringRedisTemplate.opsForValue().get("inventory001");
Integer inventory = Integer.valueOf(result);
if (inventory>0){
stringRedisTemplate.opsForValue().set("inventory001",String.valueOf(inventory-1));
retMessage = "成功卖出一件商品,剩余库存"+(inventory-1);
System.out.println(retMessage+"\t"+"服务端口:"+port);
}else{
System.out.println("库存不足,无法卖出商品,服务端口:"+port);
}
}catch (Exception e){
e.printStackTrace();
}finally {
// if (stringRedisTemplate.opsForValue().get(key).equals(uuidvalue)){
// stringRedisTemplate.delete(key);
// }
stringRedisTemplate.execute(new DefaultRedisScript<>("if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end",Long.class), Arrays.asList(key),uuidvalue);
}
return retMessage;
}
}
- 锁的可重入性:原有的setnx命令虽然可以实现基本的分布式锁,但是针对锁的可重入性缺失,因此,考虑通过hash结果进行解决:hset key k1 v1
- 通过lua脚本实现可重入锁,以及自动续期,代码示例
@Component
public class DistributedLockFactory {
@Autowired
private StringRedisTemplate stringRedisTemplate;
private String lockName;
private String uuid;
public DistributedLockFactory(){
this.uuid = UUID.randomUUID().toString();
}
public Lock getDistributedLock(String lockType){
if("redis".equals(lockType)){
return new RedisDistributedLock(stringRedisTemplate,this.lockName,uuid);
}else if("zookeeper".equals(lockType)){
return null;
}else if("mysql".equals(lockType)){
return null;
}else{
return null;
}
}
}
public class RedisDistributedLock implements Lock {
private final String lockLua = "if redis.call('exists', KEYS[1]) == 0 or redis.call('hexists', KEYS[1], ARGV[1]) == 1 then redis.call('hincrby', KEYS[1], ARGV[1], 1) redis.call('expire', KEYS[1], ARGV[2]) return 1 else return 0 end";
private final String unlocklua = "if redis.call('hexists', KEYS[1], ARGV[1]) == 0 then return nil elseif redis.call('hincrby', KEYS[1], ARGV[1], -1) == 0 then redis.call('del', KEYS[1]) return 1 else return 0 end";
private StringRedisTemplate stringRedisTemplate;
private String lockName;
private String uuidValue;
private long expireTime;
public RedisDistributedLock(StringRedisTemplate stringRedisTemplate, String lockName,String uuidValue) {
this.stringRedisTemplate = stringRedisTemplate;
this.lockName = lockName;
this.uuidValue = uuidValue+":"+Thread.currentThread().getName();
this.expireTime = 50L;
}
@Override
public void lock() {
tryLock();
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public boolean tryLock() {
try {
tryLock(-1L, TimeUnit.SECONDS);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return false;
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
if (time==-1L){
while(!stringRedisTemplate.execute(new DefaultRedisScript<>(lockLua,Boolean.class), Collections.singletonList(lockName),uuidValue,String.valueOf(expireTime))){
Thread.sleep(600);
}
renewExpire();
return true;
}
return false;
}
private void renewExpire() {
new Timer().schedule(new TimerTask() {
@Override
public void run() {
if (stringRedisTemplate.hasKey(lockName))
stringRedisTemplate.expire(lockName,expireTime,TimeUnit.SECONDS);
}
}, expireTime * 1000 / 3);
}
@Override
public void unlock() {
Long execute = stringRedisTemplate.execute(new DefaultRedisScript<>(unlocklua, Long.class), Collections.singletonList(lockName), uuidValue);
if (null == execute){
throw new IllegalMonitorStateException("释放锁失败");
}
}
@Override
public Condition newCondition() {
return null;
}
}
@Service
public class UserServiceImpl implements UserService {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String port;
@Autowired
private DistributedLockFactory distributedLockFactory;
@Override
public String userInfoHandler() {
String retMessage = "";
Lock redis = distributedLockFactory.getDistributedLock("redis");
redis.lock();
try{
String result = stringRedisTemplate.opsForValue().get("inventory001");
Integer inventory = Integer.valueOf(result);
if (inventory>0){
stringRedisTemplate.opsForValue().set("inventory001",String.valueOf(inventory-1));
retMessage = "成功卖出一件商品,剩余库存"+(inventory-1);
System.out.println(retMessage+"\t"+"服务端口:"+port);
testRentry();
}else{
System.out.println("库存不足,无法卖出商品,服务端口:"+port);
}
}catch (Exception e){
e.printStackTrace();
}finally {
redis.unlock();
}
return retMessage;
}
private void testRentry(){
Lock lock = distributedLockFactory.getDistributedLock("redis");
lock.lock();
try{
//业务逻辑
System.out.println("可重入成功");
}finally {
lock.unlock();
}
}
}
单主机场景下,主机宕机,导致锁未及时同步导致,多个客户获取同一把锁,解决方案:redisson-redlock
MultiLock
缓存淘汰策略
当redis内存不足时,为了新增数据会根据缓存淘汰算法选择一些数据进行删除数据,如何选择数据有以下几种算法:
- noeviction:不会删除任何key,如果达到了内存上面则报错
- allkeys-lru:对所有的key采用lru算法进行删除
- volatile-lru:只对设置了过期时间的key采用lru算法删除
- allkeys-random:对所有的过期key进行随机删除
- volatile-random:对设置了过期时间的key进行随机删除
- volatile-ttl:删除马上要过期的key
- allkeys-lfu:对所有的key安好lfu算法删除
- volatile-lfu:对设置了过期时间的key按照lfu算法删除
Redis五种类型源码分析
- redis五种数据类型的底层数据结构
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
}
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct redisObject {
unsigned type:4; //类型
unsigned encoding:4; //编码
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; /* Reference count */ //引用计数
void *ptr; /* Pointer to the actual data structure */
} robj;

- String
String类型的三种物理编码方式:int、raw、embstr
- int:可以保存long类型的64位有符号整数,超过long类型的范围,则编码方式变为raw
- embstr:保存长度小于44字节的字符串,超过44字节,则编码方式变为raw
- raw:保存长度大于44字节的字符串,
- 如果修改embstr类型,则不论是否超过44字节,都会变为raw类型
SDS:简单动态字符串,redis自己封装的字符串类型,redis中所有的字符串都是SDS类型
- len:记录字符串长度
- alloc:记录分配内存空间的大小
- flags:记录编码方式
- buf:字符数组,保存字符串
SDS相比于C语言的字符串的优势:
- 获取字符串长度时间复杂度为O(1)
- 杜绝缓冲区溢出
- 减少内存分配次数
- 二进制安全
- 兼容部分C字符串函数
int编码格式:当创建的数据为整数,长度小于20且小于10000时,redis会从预分配的对象中直接获取不再重新创建对象,否则创建一个整数类型对象
embstr编码格式:当创建的数据为字符串,长度小于44字节时,redis使用embstr编码格式,set设置数据时,会在创建redisobject对象后通过指针+1的形式直接在对手后面创建SDS对象,从而减少内存分配次数
raw编码格式:当创建的数据为字符串,长度大于44字节时,redis使用raw编码格式。
- Hash
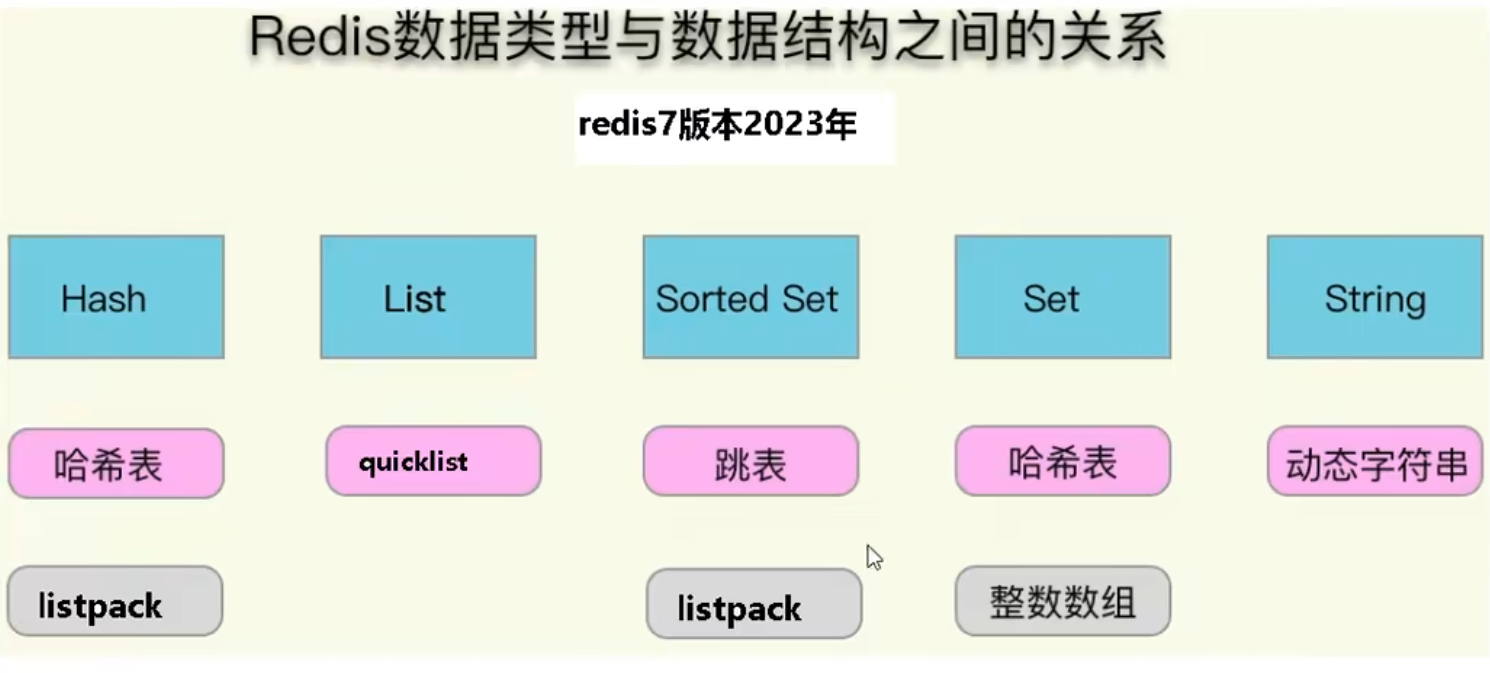
Hash结构分为redis6和redis7两个版本
- redis6:底层使用ziplist和hashtable两种数据结构,当hash对象保存的键值对数量小于512且所有键值对的长度都小于64字节时,使用ziplist编码格式,否则使用hashtable编码格式,如果一开始使用ziplist,后续数据库增加可以升级为hashtable,但是反过来不行
zipList:是一个特殊的双向链表,但是不存储指向前后的指针,只存储上一个节点的长度和当前节点的长度。一个ziplist存储的数据从前到后:1.链表的内存占用字节数,2.尾节点到起始地址的字节数,3.节点数量,4.N个节点,5.链表结尾标识
ziplist链表中的节点结构:
typedef struct zlentry { unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/ unsigned int prevrawlen; /* Previous entry len. */ unsigned int lensize; /* Bytes used to encode this entry type/len. For example- if an entry 5 bytes long (a 4 byte unsigned integer following by a 1 byte string), there is one byte used to encode the type (0x05), one to encode the length of the integer (0x04) and one to encode the string length (0x01). */ unsigned int len; /* Bytes used to represent the actual entry. For strings this is just the string length while for integers it is 1, 2, 3, 4, 8 or 0 (for 4 byte integers). */ unsigned int headersize; /* prevrawlensize + lensize. */ unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on the entry encoding. However for 4 byte integers the encoding is stored in the unsigned int len. */ unsigned char *p; /*指向当前节点的起始位置 */ } zlentry;redis7:底层使用listpack和hashtable两种数据结构,当hash对象保存的键值对数量小于512且所有键值对的长度都小于64字节时,使用listpack编码格式,否则使用hashtable编码格式,当hash对象保存的键值对数量小于512且所有键值对的长度都小于64字节时,使用listpack编码格式,否则使用hashtable编码格式
listpack的出现是由于ziplist会存在连锁更新的问题,为了解决这个问题listpack中的节点不再存储前一个节点的长度数据,因此listpack结构分为四个部分:1.用4个字节记录整个listpack的占用内存大小,2.用两个字节记录节点个数,3.N个节点,4.结束标志。
- 节点的结构:1.编码类型,2.实际的数据,3.编码类型和元素数据的总长度
List
- redis6:list=quicklist+ziplist
- redis7:list=listpack+quicklist
Quicklist
- quicklist是一个双向链表,每个节点都是一个ziplist+指向前后节点的指针,每个ziplist中存储多个数据,因此quicklist可以看作是一个由ziplist组成的双向链表,在redis7中为了解决ziplist的连锁更新问题,用listpack代替ziplist,quicklist的节点结构:
typedef struct quicklistNode { struct quicklistNode *prev; struct quicklistNode *next; unsigned char *zl; /*指向当前节点的ziplist */ unsigned int sz; /* ziplist size in bytes */ unsigned int count : 16; /* count of items in ziplist */ unsigned int encoding : 2; /* RAW==1 or LZF==2 */ unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */ unsigned int recompress : 1; /* was this node previously compressed? */ unsigned int attempted_compress : 1; /* node can't compress; too small */ unsigned int extra : 10; /* more bits to steal for future usage */ } quicklistNode;
- quicklist是一个双向链表,每个节点都是一个ziplist+指向前后节点的指针,每个ziplist中存储多个数据,因此quicklist可以看作是一个由ziplist组成的双向链表,在redis7中为了解决ziplist的连锁更新问题,用listpack代替ziplist,quicklist的节点结构:
Set
set结构一致没有变化,如果数据是数值类型且数量小于512(默认)则使用intset,否则使用hashtable
Zset
- redis6:底层使用ziplist和skiplist两种数据结构,当有序集合保存的元素数量小于128且所有元素成员的长度都小于64字节时,使用ziplist编码格式,否则使用skiplist编码格式,如果一开始使用ziplist,后续数据库增加可以升级为skiplist,但是反过来不行
- redis7:底层使用listpack和skiplist两种数据结构,当有序集合保存的元素数量小于128且所有元素成员的长度都小于64字节时,使用listpack编码格式,否则使用skiplist编码格式,如果一开始使用listpack,后续数据库增加可以升级为skiplist,但是反过来不行
- skiplist的节点结构:
typedef struct zskiplistNode { sds ele; //成员对象 double score; //分数 struct zskiplistNode *backward; //指向前一个节点的指针 struct zskiplistLevel { struct zskiplistNode *forward; //指向下一个节点的指针 unsigned long span; //跨度,记录当前节点到下一个节点的距离 } level[]; //层,每一层都有一个指向下一个节点的指针和跨度 } zskiplistNode;
skipList:跳表指的是可以实现二分查找的有序链表,跳表是一种随机化的数据结构,基于并联的链表,其效率可以和平衡树相媲美,跳表在链表的基础上增加了多级索引,通过多级索引可以快速定位到链表的某一位置,从而提高查找效率,跳表的时间复杂度为O(logn),空间复杂度为O(n)
Redis底层通信原理分析-多路复用原理
- 多路复用是非阻塞IO模型,底层支持是epoll,原来是select后来是poll最终是epoll。
- select:底层使用数组存储fd,当fd数量超过1024时,需要重新分配内存,效率低,而且每次都需要遍历fd,效率低
- poll:底层使用链表存储fd,当fd数量可以超过1024时,不需要重新分配内存,效率高,但是每次都需要遍历fd,效率低
- epoll:底层使用红黑树存储fd,当fd数量超过1024时,不需要重新分配内存,效率高,给每个fd注册一个回调函数,当事件就绪则通过回调函数加入就绪列表,只需要便利列表即可



