Zookeeper简介
- ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
- 可以实现负载均衡,注册中心,分布式锁等功能
Zookeeper安装配置解读
zoo.cfg文件中包含以下相关重要配置信息
- tickTime:通信心跳事件,zk服务器与客户端之间的通信间隔,或者是zk服务集群之间的通信间隔
- initLimit:初次连接不能超过的时间,
- syncLimit:主从同步时不能超过的时间,超过就认为死亡
- dataDir:zk数据存储的目录(一般为zkData)
- clientPort:zk的端口
zk的集群配置,
- 在zk安装目录下创建zkData目录,并在此目录下新建myid文件,在文件中用数字标明此服务的id
- 需要在每个zk服务的zoo.cfg文件目录下都记录整个集群的信息
<!-- 其中A为各个服务器的myid,B为各个服务器的IP,C为主机与从机交互的端口,D为选举的端口 --> server.A=B:C:D server.1=192.168.18.87:2888:3888 server.2=192.168.18.86:2888:3888 server.3=192.168.18.85:2888:3888
Zookeeper选举操作
zk第一次的选举过程较为简单,首先在zoo.cfg文件中已经明确知道有几台服务器,某台服务器得到超过半数的投票即成为主机,第一次选举时,每个服务都会投自己一票,但是如果发现有比自己myid大的服务器就会放弃投自己的票,转而投给myid大的服务。当选举出来主机之后,再上线的服务就会直接把票给主机。此外,还需要明确三个变量。如果不是第一次选举,则按照规则:epoch大的胜出;epoch相同时,zxid大的胜出;zxid相同时,myid大的胜出。
- SID:服务器的ID,即myid文件中的数字
- ZXID:客户端对服务器发起一些操作时,回更新这个变量,集群中的所有zk服务可能不一定完全一样,有的回不一样,因此,当出现服务宕机时,会优先考虑ZXID大的服务作为主机
- EPOCH:如果集群中已经有leader,每投完一次票,leader的EPOCH就会+1
Zookeeper命令行操作
# 启动ZK
# 在ZK的目录bin下运行zk.sh
zkServer.sh start
# 查看服务状态
zkServer.sh status
# 停止服务
zkServer.sh stop
# 重启服务
zkServer.sh restart
# 启动服务后,可以通过以下命令链接zk
zkServer.sh --server 127.0.0.1:2181
# 链接上服务器之后进行服务内部,可以通过以下命令进行操作
# zk服务类似与linux系统,数据存储的方式也是节点方式,通过以下命令查询当前目录下的数据
ls /node -s[附件次级的信息] -w[监听此节点数量的变化]
# 获取节点数据
get /node -s[附件次级的信息] -w[监听此节点数据的变化]
# 创建节点,默认无序列,永久节点
create /node "节点的数据" -s[含有序列] -e[临时节点,会因为重启而删除]
# 设置节点的数据
set /node "节点的数据"
# 查看节点的状态
stat /node
# 删除节点
delete /node
# 递归删除节点
deleteall /node
节点信息
- czxid:创建节点的事务ID
- ctime:节点被创建的时间
- mzxid:最后更新的事务zxid
- mtime:节点最后更新的时间
- pzxid:最后更新的子节点的id
- cversion:节点的子节点变化号,就是子节点变化的次数
- dataversion:节点数据的变化号
- aclversion:访问控制列表的变化号
- ephemeralOwner:临时检点的拥有者session,如果不是临时节点就是0
- datalength:节点数据的长度
- numChildern:节点拥有子节点的数量
zk服务监听原理
在客户端创建连接到zk服务的过程中,会创建两个线程,一个线程用于监听zk的服务变化,一个线程用于与zk连接。当客户端需要监听zk服务中某些事件的时候,连接线程会将监听事件注册到zk服务的监听列表中,如果zk服务发生了变化,则会调用监听列表中的方法将消息发送给客户端,此时客户端会通过监听线程进行操作。注意,连接线程注册一次监听事件就只会监听一次,如果监听事件被触发了之后就不会再监听。所以如果需要持续监听则在监听的回调函数中再次监听即可。
zk客户端向服务器写数据的流程
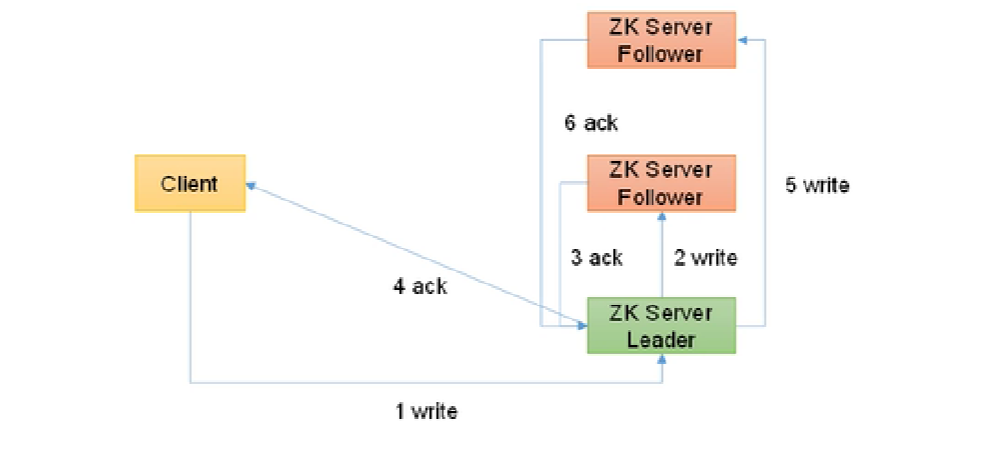
- 如果客户端访问的是主机器,流程图如下图
- 首先客户端发起写数据请求到主机器上
- 主机器写完数据后,发送写请求到一台从机上
- 从机写完数据后,发送确认消息给主机器
- 主机器接收到从机的消息之后,确认半数以上的节点已经完成数据同步就返回确认消息给客户端
- 随后再让其他从机同步数据
- 所有从机写完数据之后都会通知主机
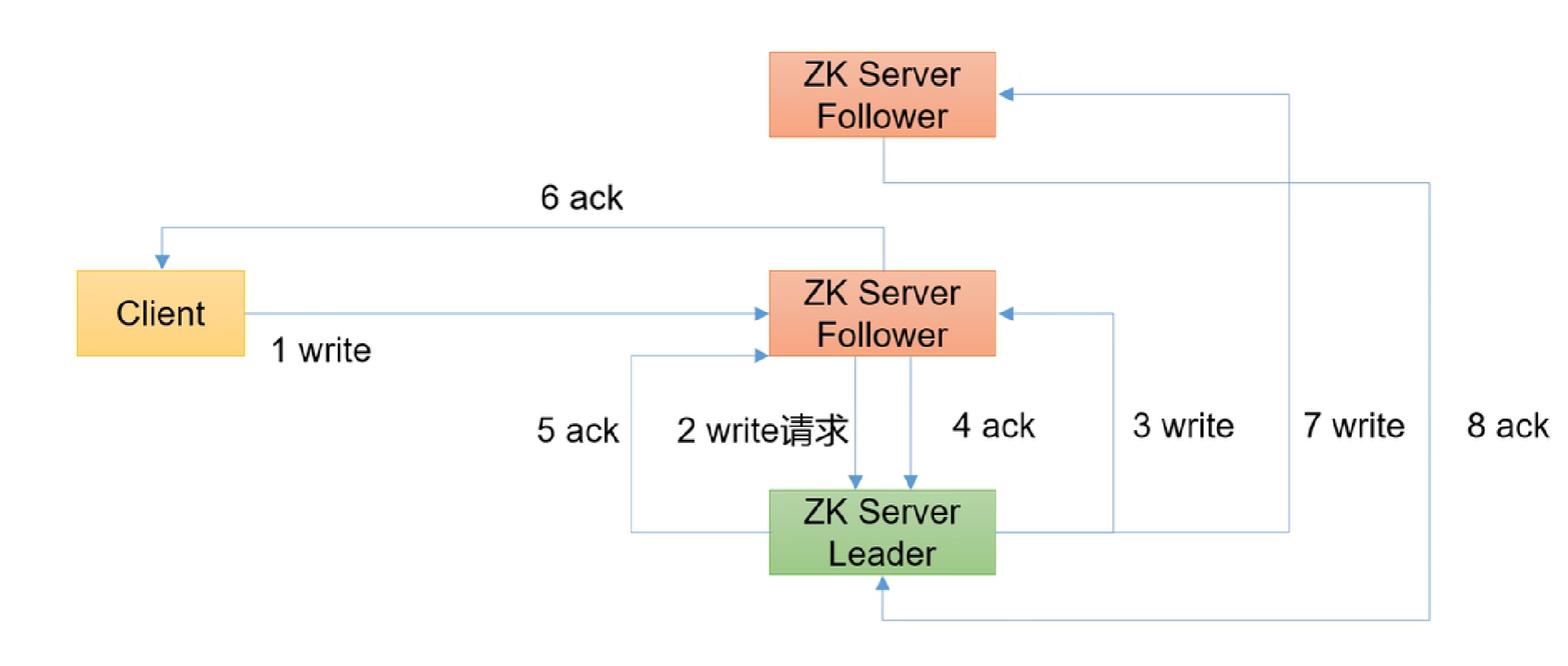
- 如果客户端访问的是从机,流程如下图
- 首先客户端发起写请求给从机
- 从机将写请求转发给主机
- 主机写完数据之后,发通知给从机写数据
- 从机写完数据之后通知主机
- 主机接受到通知后,发现半数机器都已经同步完成后就通知一开始的从机
- 从机收到主机的通知之后就返回确认的消息给客户端
- 随后主机再通知其他从机写数据
- 所有的从机同步完后都通知主机
代码实战
- 通过API连接ZK,创建节点,获取子节点,判断节点是否存在
public class ZkClient{
private String connectionString = "127.0.0.1:2181";
private Integer SessionTimeout = 2000;
private ZooKeeper zkclient;
public static void main(String[] args) {
ZkClient zkClient = new ZkClient();
zkClient.init();
zkClient.createNode();
zkClient.getChildren();
zkClient.exist();
}
@SneakyThrows
public void init() {
zkclient = new ZooKeeper(connectionString, SessionTimeout, watchedEvent -> {
System.out.println("================================");
List<String> children = null;
try {
children = zkclient.getChildren("/",true);
} catch (KeeperException | InterruptedException e) {
throw new RuntimeException(e);
}
for (String item : children){
System.out.println(item);
}
System.out.println("================================");
});
}
// 创建一个节点
@SneakyThrows
public void createNode(){
// 第一个参数:节点名称,第二个参数:节点的数据内容,第三个参数:节点的访问权限,第四个参数:创建的模式(是否是临时节点,是否带有序列)
zkclient.create("/lujietest","this is test content".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
}
// 获取子节点信息
@SneakyThrows
public void getChildren() {
// 第一个参数:节点的名称,第二个参数是否监听此节点的变化
List<String> children = zkclient.getChildren("/",true);
for (String item : children){
System.out.println(item);
}
}
// 判断节点是否存在
@SneakyThrows
public void exist(){
// 第一个参数:节点名称,第二个参数:是否监听此节点
Stat stat = zkclient.exists("/lujietest",false);
System.out.println(stat==null?"not exist":"exist");
}
}- 服务动态上下线通知,代码分为服务器端和客户端两个部分
// 服务端代码
public class Server{
private String connectionString = "127.0.0.1:2181";
private Integer SessionTimeout = 2000;
public static void main(String[] args) throws InterruptedException {
Server server = new Server();
ZooKeeper zkClient = server.getConnection();
server.regist(zkClient,args[0]);
// 保持线程存活
Thread.sleep(Long.MAX_VALUE);
}
// 建立连接
@SneakyThrows
public ZooKeeper getConnection(){
return new ZooKeeper(connectionString, SessionTimeout, new Watcher(){
@Override
@SneakyThrows
public void process(WatchedEvent watchedEvent){
}
});
}
// 注册服务到zk上,其实就是创建一个节点
@SneakyThrows
public void regist(ZooKeeper zkclient, String hostName){
// 注意要创建临时节点且带有序列号,这样服务下线之后才会被感知到
zkclient.create("/Servers/"+hostName,hostName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
}
public class Client{
private String connectionString = "127.0.0.1:2181";
private Integer SessionTimeout = 200000;
private ZooKeeper zkClient;
public static void main(String[] args) throws InterruptedException {
Client client = new Client();
client.getConnection();
client.getServers();
// 保持线程存活
Thread.sleep(Long.MAX_VALUE);
}
// 建立连接
@SneakyThrows
public void getConnection(){
zkClient = new ZooKeeper(connectionString, SessionTimeout, watchedEvent -> getServers());
}
// 获取所有服务节点
@SneakyThrows
public void getServers(){
System.out.println("==========================================");
List<String> children = zkClient.getChildren("/Servers",true);
for (String item : children){
// 获取节点的数据内容,第一个参数:节点路径,第二个参数:是否监听,第三个参数:状态
byte[] data = zkClient.getData("/Servers/"+item,false,null);
System.out.println(new String(data));
}
System.out.println("==========================================");
}
}
- ZK实现分布式锁
public class ZkDistributeLock {
private String connectionString = "127.0.0.1:2181";
private Integer SessionTimeout = 2000;
private ZooKeeper zkclient;
private CountDownLatch countDownLatch = new CountDownLatch(1);
private CountDownLatch countDownLatchWait = new CountDownLatch(1);
private String waitpath;
private String node;
public static void main(String[] args) throws InterruptedException {
}
public ZkDistributeLock() throws Exception{
getConnection();
countDownLatch.await();
Stat exist = exist();
if (exist==null){
//创建根节点
zkclient.create("/lock","lockNode".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
@SneakyThrows
private void getConnection(){
zkclient = new ZooKeeper(connectionString, SessionTimeout, new Watcher(){
@Override
@SneakyThrows
public void process(WatchedEvent watchedEvent){
// 判断是否连接成功
if (watchedEvent.getState() == Event.KeeperState.SyncConnected){
countDownLatch.countDown();
}
// 判读是否是删除事件,并且是等待的节点被删除
if (watchedEvent.getType()== Event.EventType.NodeDeleted && watchedEvent.getPath().equals(waitpath)){
countDownLatchWait.countDown();
}
}
});
}
// 加锁
@SneakyThrows
public void zkLock(String lockName){
// 创建节点
node = zkclient.create("/lock/seq-", lockName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
List<String> children = zkclient.getChildren("/lock", false);
if (children.size()==1){
return;
}else{
// 判断节点是否是最小的节点,如果不是就监听前一个节点
Collections.sort(children);
String substring = node.substring("/lock/".length());
int index = children.indexOf(substring);
if (index==-1){
System.out.println("数据异常");
}else if( index ==0){
return;
}else{
waitpath = "/lock/" + children.get(index - 1);
zkclient.getData(waitpath, true, null);
countDownLatchWait.await();
return;
}
}
System.out.println("获取锁成功"+lockName);
}
// 释放锁
@SneakyThrows
public void unlock(){
zkclient.delete(node,-1);
}
// 判断节点是否存在
@SneakyThrows
public Stat exist(){
// 第一个参数:节点名称,第二个参数:是否监听此节点
return zkclient.exists("/lock",false);
}
}
public class ZktestApplication {
public static void main(String[] args) throws Exception {
final ZkDistributeLock zkDistributeLock = new ZkDistributeLock();
final ZkDistributeLock zkDistributeLock1 = new ZkDistributeLock();
new Thread(()->{
zkDistributeLock.zkLock("testlock1");
System.out.println("第一个获取到锁");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
zkDistributeLock.unlock();
System.out.println("第一个释放锁");
}).start();
new Thread(()->{
zkDistributeLock1.zkLock("testlock2");
System.out.println("第二个获取到锁");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
zkDistributeLock1.unlock();
System.out.println("第二个释放锁");
}).start();
}
}
- 通过框架实现zk分布式锁
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>4.3.0</version>
</dependency>public class ZktestApplication {
public static void main(String[] args) throws Exception {
InterProcessMutex lock = new InterProcessMutex(getCuratorFramework(), "/lock");
InterProcessMutex lock1 = new InterProcessMutex(getCuratorFramework(), "/lock");
new Thread(new Runnable() {
@Override
@SneakyThrows
public void run() {
lock.acquire();
System.out.println("1-1获取锁");
lock.acquire();
System.out.println("1-2获取锁");
lock.release();
System.out.println("1-1释放锁");
lock.release();
System.out.println("1-2释放锁");
}
}).start();
new Thread(new Runnable() {
@Override
@SneakyThrows
public void run() {
lock1.acquire();
System.out.println("2-1获取锁");
lock1.acquire();
System.out.println("2-2获取锁");
lock1.release();
System.out.println("2-1释放锁");
lock1.release();
System.out.println("2-2释放锁");
}
}).start();
}
private static CuratorFramework getCuratorFramework() {
CuratorFramework build = CuratorFrameworkFactory.builder().connectString("127.0.0.1:2181").connectionTimeoutMs(2000).sessionTimeoutMs(2000)
.retryPolicy(new ExponentialBackoffRetry(3000, 3)).build();
build.start();
return build;
}
}
Paxos算法
作为共识算法,原理如下:
- Proposer:提议者,起草提议
- Acceptor:接收者
- Learner:学习者
Paxos算法分为两个阶段。具体如下:
阶段一:
Proposer选择一个提案编号N,然后向半数以上的Acceptor发送编号为N的Prepare请求。
如果一个Acceptor收到一个编号为N的Prepare请求,且N大于该Acceptor已经响应过的所有Prepare请求的编号,那么它就会将它已经接受过的编号最大的提案(如果有的话)作为响应反馈给Proposer,同时该Acceptor承诺不再接受任何编号小于N的提案。
阶段二:
如果Proposer收到半数以上Acceptor对其发出的编号为N的Prepare请求的响应,那么它就会发送一个针对
[N,V]提案的Accept请求给半数以上的Acceptor。注意:V就是收到的响应中编号最大的提案的value,如果响应中不包含任何提案,那么V就由Proposer自己决定。如果Acceptor收到一个针对编号为N的提案的Accept请求,只要该Acceptor没有对编号大于N的Prepare请求做出过响应,它就接受该提案。
问题1:Pa提议N获得半数以上承诺,然后提议N,获取半数以上接受,但是接收者再回复Pa之前,收到了Pb提议的N+1请求,于是接收者回复了Pa,但是又承诺了Pb,导致后续Pb又进行了提议N+1,并且获得通过,导致了不一致
问题2:Pa提议N获得半数以上承诺,然后提议N,结果接收者又收到了Pb的N+1提议,于是又转头承诺Pb,这是Pa提议N没有收到半数以上的接受回应又发起N+2,于是接收者又转头承诺Pa,导致Pb的提议又没有收到回应,于是Pb又开始N+3提议,死循环
Zab协议
Zab协议为了防止出现以上的问题,就进行了选举,保证只有一个leader即可.Zab协议包括两种模式:消息广播以及崩溃恢复
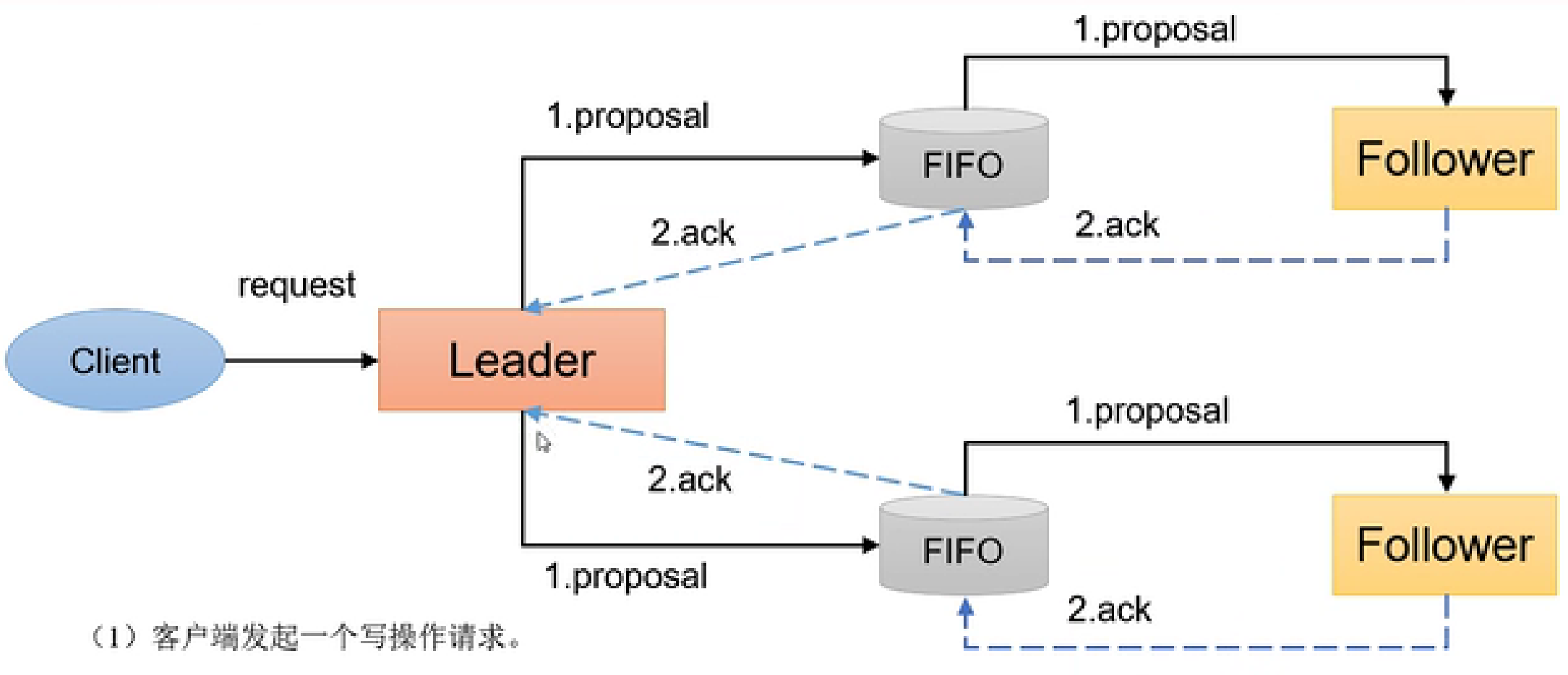
- 消息广播
消息广播的集体流程如下图:客户端发起请求后,由leader发起一个提案,等半数以上的follower回应执行之后,发起提交请求,等待半数以上的follower完成之后直接回应客户端完成。如果有其他follower没有完成的就不再执行了,等后续其他节点同步即可
- 崩溃恢复
根据消息广播阶段的流程,可以知道事务处理的流程分为两个阶段:提案阶段和提交阶段。
通常leader无法与半数以上的follower进行通信即可视为崩溃,崩溃恢复需要保证两点:
- 已经执行的事务不能丢失
- 没有执行的事务不能继续执行
CAP
C:一致性(机器越少一致性越高,如果只有一台机器那么一致性就是绝对的)
A:可用性(服务请求最新数据的延迟,不能超过阈值,如果要求请求的实时性高,那么留给不同机器同步数据从而保持一致性的时间就越少,如果机器多那就不行)
P:分区容错(容错性高,机器越多越好,这样即使有的机器故障也可以)



