深度学习之语义分割PSPNet(2016)
PSPNet网络简介
接续上一期的FCN语义分割网络,本章讲述在其后出现的又一较为流行的网络PSPNet。PSPNet相较于之前的SegNet和U-Net的改进还是比较明显的,改进的地方就在于引入了PPM模块。
什么是PPM模块?其实所谓的PPM(pyramid pooling module)顾名思义就是金字塔池化模型。和我们熟知的FPN特征金字塔比较相似,它通过对最后的特征层进行不同大小的平均池化,然后再将其堆叠起来,其中池化分为四个部分:1x1,2x2,3x3,6x6。将最后的18x18大小的特征层调整为对应的四个大小,然后进行特征提取。具体如下图。
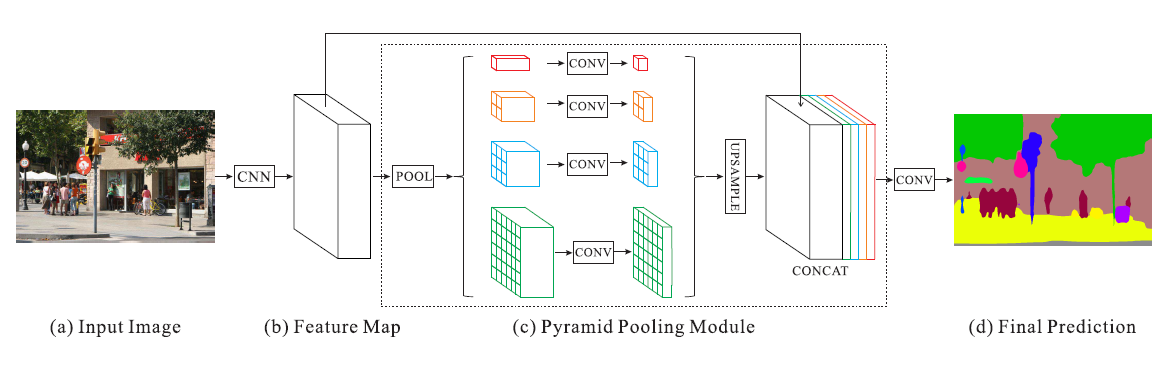
关于PSPNet的loss函数,本文将在代码中给出。其中主要分为两个部分,一个部分是主干特征提取网络的倒数第二层进行调整通道和大小,然后与对应的GT进行计算aux_loss,另一部分是经过PPM模块后再调整通道和大小的特征与对应的GT计算的main_loss。
此次文章使用的主干网络为ResNet101,下面给出代码:
ResNet101
class Conv_block(nn.Module):
def __init__(self,input_channel,filters,stride=2):
super(Conv_block,self).__init__()
self.conv1 = nn.Conv2d(input_channel,filters[0],kernel_size=1,stride = stride,bias=True)
self.batch1 = nn.BatchNorm2d(filters[0])
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(filters[0],filters[1],kernel_size=3,stride=1,padding =1,bias =True)
self.batch2 = nn.BatchNorm2d(filters[1])
self.relu2 = nn.ReLU()
self.conv3 = nn.Conv2d(filters[1],filters[2],kernel_size=1,stride=1,bias =True)
self.batch3 = nn.BatchNorm2d(filters[2])
self.conv4 = nn.Conv2d(input_channel,filters[2],kernel_size=1,stride=stride,bias =True)
self.batch4 = nn.BatchNorm2d(filters[2])
self.relu3 = nn.ReLU()
def forward(self,x):
shortcut = x
x = self.conv1(x)
x = self.batch1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.batch2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.batch3(x)
shortcut = self.conv4(shortcut)
shortcut = self.batch4(shortcut)
x +=shortcut
x = self.relu3(x)
return xclass Identity_block(nn.Module):
def __init__(self,input_channel,filters):
super(Identity_block,self).__init__()
self.conv1 = nn.Conv2d(input_channel,filters[0],kernel_size=1,stride=1,bias=True)
self.batch1 = nn.BatchNorm2d(filters[0])
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(filters[0],filters[1],kernel_size=3,padding=1,stride=1,bias=True)
self.batch2 = nn.BatchNorm2d(filters[1])
self.relu2 = nn.ReLU()
self.conv3 = nn.Conv2d(filters[1],filters[2],kernel_size=1,stride=1,bias=True)
self.batch3 = nn.BatchNorm2d(filters[2])
self.relu3 = nn.ReLU()
def forward(self,x):
shortcut = x
x = self.conv1(x)
x = self.batch1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.batch2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.batch3(x)
x +=shortcut
x = self.relu3(x)
return x
class ResNet101(nn.Module):
def __init__(self,num_classes):
super(ResNet101,self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,padding=3,stride=2,bias=True),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.model2 = nn.Sequential(
Conv_block(64,[64,64,256],stride=1),
Identity_block(256,[64,64,256]),
Identity_block(256,[64,64,256])
)
self.model3 = nn.Sequential(
Conv_block(256,[128,128,512]),
Identity_block(512,[128,128,512]),
Identity_block(512,[128,128,512]),
Identity_block(512,[128,128,512])
)
self.conv1 = Conv_block(512,[256,256,1024])
self.loop_identity = Identity_block(1024,[256,256,1024])
self.model4 = nn.Sequential(
Conv_block(1024,[512,512,2048]),
Identity_block(2048,[512,512,2048]),
Identity_block(2048,[512,512,2048])
)
def forward(self,x):
c1 = x = self.model1(x)
c2 = x = self.model2(x)
c3 = x = self.model3(x)
x = self.conv1(x)
for i in range(22):
x = self.loop_identity(x)
c4 = x
c5 = x = self.model4(x)
return c2,c3,c4,c5
PPM模块
class PPM(nn.Module):
def __init__(self,input_channel,reduction_dim,pool_size):
super(PPM,self).__init__()
self.features_pool = []
for i in pool_size:
self.features_pool.append(nn.Sequential(
nn.AdaptiveAvgPool2d(i),
nn.Conv2d(input_channel, reduction_dim, kernel_size=1, bias=False),
nn.BatchNorm2d(reduction_dim),
nn.ReLU(inplace=True)
))
self.features_pool = nn.ModuleList(self.features_pool)
def forward(self,x):
x_size = x.size()
out = [x]
for f in self.features_pool:
out.append(F.interpolate(f(x),x_size[2:],mode = 'bilinear',align_corners =True))
return torch.cat(out,1)PSPNet网络结构
class PSPNet(nn.Module):
def __init__(self,num_classes,training = True):
# input_shape = 576x576
super(PSPNet,self).__init__()
self.training = training
self.resnet = ResNet101(num_classes)
self.criterion = nn.CrossEntropyLoss(ignore_index=255)
self.ppm = PPM(2048,512,[1,2,3,6])
self.cls = nn.Sequential(
nn.Conv2d(4096, 512, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout2d(),
nn.Conv2d(512, num_classes, kernel_size=1)
)
self.aux = nn.Sequential(
nn.Conv2d(1024, 256, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout2d(),
nn.Conv2d(256, num_classes, kernel_size=1)
)
def forward(self,x,target=None):
input_size = x.size()
layer = self.resnet(x)
#取layer4层的特征层
x = layer[3]
#PPM金字塔池化模型
x = self.ppm(x)
# 调整通道数=num_classes,可以简单的认为就是将后续的全连接层换成卷积层进行学习
x = self.cls(x)
#双线性差值调整size
x = F.interpolate(x,size=(input_size[2],input_size[3]),mode = 'bilinear',align_corners = True)
# 辅助的loss计算
if self.training :
#调整辅助层通道数
aux = self.aux(layer[2])
aux = F.interpolate(aux,size=(input_size[2],input_size[3]),mode = 'bilinear',align_corners = True)
main_loss = self.criterion(x,y)
aux_loss = self.criterion(aux,y)
# x.max(1)[1]用于计算标准
return x.max(1)[1],main_loss,aux_loss
return x


