深度学习之语义分割SegNet(2015)
what is SegNet?
Emmmmm,从这篇文章开始应该会集中更新语义分割系列的算法模型,主要是科研的需求吧,应该会针对所有比较流行的语义分割的算法进行总结,以及讲解,针对各种算法的特点进行体现,而其中利用的主干特征提取的网络会在之前讲解过的特征提取网络中选择。总的来说,接下来一段时间会集中更新语义分割的相关系列算法,并对其中比较优秀的算法进行代码方面的实现。So,接下来就开始我们的第一次更新的内容吧——SegNet。
想要了解SegNet,那我们首先要对语义分割这个概念进行了解。所谓的语义分割其实就是针对图像中的像素进行分类,判断每个像素所属的类别,这就是我们需要做的任务,其实从根本上来看,就是像素的多分类问题。

语义分割在实际生活中的应用主要体现在医学影像和无人驾驶方面,在医学影像中主要用于对一些图像中的异常(如肿瘤)进行分割,辅助医生对病人的病情进行判断。在无人驾驶中,语义分割的作用就体现在对道路、车辆、行人、道路标识等一些物体的判断,如果语义分割能够对这些方面做得很好,那么对于社会的发展将是一个重要的推动力。
而SegNet网络就是语义分割算法的一种,其网络结构符合语义分割算法的基本结构特征,主要包括编码和解码两个过程,根据最后的解码结果与真实值之间的比较训练模型参数。主要过程就是先通过特征提取进行降维,再进行上采样升维得到一个具有一定会长宽的特层。
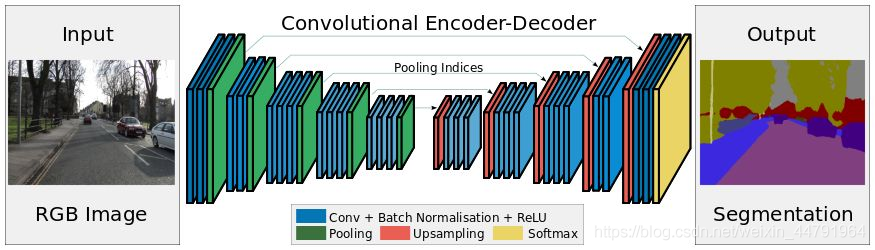
主干网络结构简介
针对SegNet算法,其网络结构主要包括编码和解码两个部分。编码部分即特征提取部分,选择ResNet50作为特征提取的网络。在之前的文章中我们已经介绍过了ResNet101,相比于ResNet101的网络结构,ResNet50只在其中的Identity基础块的重复次数降低了,其余部分并没有过多的变化,其网络结构如下图:

ResNet50网络的主要流程:
- 由于第一层7x7卷积,所以在卷积前加入
ZeroPadding2D,然后如同图中所示,归一化接一层激活和池化 - 第二层一次
Conv_block、两次identity_block - 第三层一次
Conv_block、三次identity_block - 第四层一次
Conv_block、五次identity_block - 第五层一次
Conv_block、两次identity_block
代码如下:
def identity_block(input_tensor, kernel_size, filters, stage, block):
filters1, filters2, filters3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# 1x1压缩
x = Conv2D(filters1, (1, 1) , name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
# 3x3提取特征
x = Conv2D(filters2, kernel_size , data_format=IMAGE_ORDERING , padding='same', name=conv_name_base + '2b')(x)
x = BatchNormalization(name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
# 1x1扩张特征
x = Conv2D(filters3 , (1, 1), name=conv_name_base + '2c')(x)
x = BatchNormalization(name=bn_name_base + '2c')(x)
# 残差网络
x = layers.add([x, input_tensor])
x = Activation('relu')(x)
return x
# 与identity_block最大差距为,其可以减少wh,进行压缩
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)):
filters1, filters2, filters3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# 1x1压缩
x = Conv2D(filters1, (1, 1) , strides=strides, name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
# 3x3提取特征
x = Conv2D(filters2, kernel_size , padding='same', name=conv_name_base + '2b')(x)
x = BatchNormalization(name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
# 1x1扩张特征
x = Conv2D(filters3, (1, 1) , name=conv_name_base + '2c')(x)
x = BatchNormalization(name=bn_name_base + '2c')(x)
# 1x1扩张特征
shortcut = Conv2D(filters3, (1, 1) , strides=strides, name=conv_name_base + '1')(input_tensor)
shortcut = BatchNormalization(name=bn_name_base + '1')(shortcut)
# add
x = layers.add([x, shortcut])
x = Activation('relu')(x)
return x
def get_resnet50_encoder(input_height=224 , input_width=224):
assert input_height%32 == 0
assert input_width%32 == 0
img_input = Input(shape=(input_height,input_width , 3 ))
x = ZeroPadding2D((3, 3))(img_input)
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x)
# f1是hw方向压缩一次的结果
f1 = x
x = BatchNormalization(name='bn_conv1')(x)
x = Activation('relu')(x)
x = MaxPooling2D((3, 3) , strides=(2, 2))(x)
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
# f2是hw方向压缩两次的结果
f2 = x
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
# f3是hw方向压缩三次的结果
f3 = x
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
# f4是hw方向压缩四次的结果
f4 = x
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')
# f5是hw方向压缩五次的结果
f5 = x
x = AveragePooling2D((7, 7) , name='avg_pool')(x)
return img_input , [f1 , f2 , f3 , f4 , f5 ]特征解码
在特征解码部分,主要是针对前面编码部分提取出来的特征进行解码,然后为每个像素进行分类,获取loss值进行训练。其中解码部分主要就是对应于之前提取到的特征进行上采样,将特征纬度不断扩大。
代码如下:
def segnet_decoder( f , n_classes, n_up=3 ):
assert n_up >= 2
o = f
o = ZeroPadding2D((1,1))(o)
o = Conv2D(512, (3, 3), padding='valid')(o)
o = BatchNormalization()(o)
# 进行一次UpSampling2D,此时hw变为原来的1/8
o = UpSampling2D((2,2))(o)
o = ZeroPadding2D((1,1))(o)
o = Conv2D( 256, (3, 3), padding='valid')(o)
o = BatchNormalization()(o)
# 进行一次UpSampling2D,此时hw变为原来的1/4
for _ in range(n_up-2):
o = UpSampling2D((2,2))(o)
o = ZeroPadding2D((1,1))(o)
o = Conv2D( 128 , (3, 3), padding='valid')(o)
o = BatchNormalization()(o)
# 进行一次UpSampling2D,此时hw变为原来的1/2
o = UpSampling2D((2,2) )(o)
o = ZeroPadding2D((1,1) )(o)
o = Conv2D( 64 , (3, 3), padding='valid' )(o)
o = BatchNormalization()(o)
# 此时输出为h_input/2,w_input/2,nclasses
o = Conv2D(n_classes , (3, 3), padding='same')( o )
return o
def _segnet(n_classes , encoder, input_height=416, input_width=416 , encoder_level=3):
# encoder通过主干网络
img_input , levels = encoder( input_height=input_height , input_width=input_width )
# 获取hw压缩四次后的结果
feat = levels[encoder_level]
# 将特征传入segnet网络
o = segnet_decoder(feat, n_classes, n_up=3 )
# 将结果进行reshape
o = Reshape((int(input_height/2)*int(input_width/2), -1))(o)
o = Softmax()(o)
model = Model(img_input,o)
return model
def resnet50_segnet( n_classes , input_height=416, input_width=416 , encoder_level=3):
model = _segnet( n_classes , get_resnet50_encoder , input_height=input_height, input_width=input_width , encoder_level=encoder_level)
return model根据以上的代码,我们很容易看出,解码部分对应于编码的部分,通过不断的上采样将特征放大到原来图片的1/2的大小然后输出分类。
至此,关于SegNet代码的所有内容就基本讲完了,下一张会讲解医学影像处理常用的语义分割网络U-net。
##2021年4月23日再次更新
在SegNet网络中,之前的代码在编码和解码的过程中没有考虑池化索引这个特点,直接通过池化和上采样层进行操作,没有添加池化索引。在实际的训练过程中,不添加池化索引这个特点有可能会导致loss值在训练过程中不太稳定,不过在运用过程中不会造成太大误差。不过在这里还是补上池化索引的功能,关于池化索引的相关特点可以百度一下。
代码如下:
from keras.engine import Layer
import keras.backend as K
class MaxPoolingWithArgmax2D(Layer):
def __init__(self, pool_size=(2, 2), strides=(2, 2), padding='same', **kwargs):
super(MaxPoolingWithArgmax2D, self).__init__(**kwargs)
self.padding = padding
self.pool_size = pool_size
self.strides = strides
def call(self, inputs, **kwargs):
padding = self.padding
pool_size = self.pool_size
strides = self.strides
if K.backend() == 'tensorflow':
ksize = [1, pool_size[0], pool_size[1], 1]
padding = padding.upper()
strides = [1, strides[0], strides[1], 1]
output, argmax = K.tf.nn.max_pool_with_argmax(inputs, ksize=ksize, strides=strides, padding=padding)
else:
errmsg = '{} backend is not supported for layer {}'.format(K.backend(), type(self).__name__)
raise NotImplementedError(errmsg)
argmax = K.cast(argmax, K.floatx())
return [output, argmax]
def compute_output_shape(self, input_shape):
ratio = (1, 2, 2, 1)
output_shape = [dim // ratio[idx] if dim is not None else None for idx, dim in enumerate(input_shape)]
output_shape = tuple(output_shape)
return [output_shape, output_shape]
def compute_mask(self, inputs, mask=None):
return 2 * [None]
class MaxUnpooling2D(Layer):
def __init__(self, up_size=(2, 2), **kwargs):
super(MaxUnpooling2D, self).__init__(**kwargs)
self.up_size = up_size
def call(self, inputs, output_shape=None):
updates, mask = inputs[0], inputs[1]
with K.tf.variable_scope(self.name):
mask = K.cast(mask, 'int32')
input_shape = K.tf.shape(updates, out_type='int32')
# calculation new shape
if output_shape is None:
output_shape = (input_shape[0], input_shape[1] * self.up_size[0], input_shape[2] * self.up_size[1], input_shape[3])
# calculation indices for batch, height, width and feature maps
one_like_mask = K.ones_like(mask, dtype='int32')
batch_shape = K.concatenate([[input_shape[0]], [1], [1], [1]], axis=0)
batch_range = K.reshape(K.tf.range(output_shape[0], dtype='int32'), shape=batch_shape)
b = one_like_mask * batch_range
y = mask // (output_shape[2] * output_shape[3])
x = (mask // output_shape[3]) % output_shape[2]
feature_range = K.tf.range(output_shape[3], dtype='int32')
f = one_like_mask * feature_range
# transpose indices & reshape update values to one dimension
updates_size = K.tf.size(updates)
indices = K.transpose(K.reshape(K.stack([b, y, x, f]),[4, updates_size]))
values = K.reshape(updates, [updates_size])
ret = K.tf.scatter_nd(indices, values, output_shape)
return ret
def compute_output_shape(self, input_shape):
mask_shape = input_shape[1]
return (mask_shape[0], mask_shape[1] * self.up_size[0], mask_shape[2] * self.up_size[1], mask_shape[3])在此处自定义了下采样代码和上采样的代码,在实际的运用中,需要将池化和上采样的代码替换为上文的代码。形如:
o = MaxPoolingWithArgmax2D()(input)
o2 = MaxUnpooling2D()(o)其中o输出的是输出层和对应的argmax参数,对应的上采样层输入就是池化层的输出和索引参数。
loss函数
在SegNet模型中,预测值是经过解码后的特征层的一维序列,对应的真实值就是图片ground truth的一维序列,在loss函数的设计中,本文采用了标准的交叉熵CE作为SegNet的loss函数。


